Case Study
1 Introduction
Your application has secrets. If those secrets leak, you may have to urgently update them and redeploy applications. Leaked secrets can cost you in man-hours, in reputation, and in revenue.
Haven is an open-source solution for easily and securely managing those application secrets. Haven abstracts away the complexity of secrets management for software engineers, so they can have the peace of mind to focus on their most important work. In this case study, we describe how we designed and built Haven, along with some of the technical challenges we encountered. But first, let’s start with an overview of secrets.
2 Secrets
2.1 What is a secret?
A secret is something you want to keep secret. More specifically, it's a sensitive piece of data that authenticates or authorizes you to a system. [1] For example, a connection string that you pass to a database so you can authenticate a session and request data from it. Or an API token that you supply when you make a call to your cloud provider so you can read and write from its storage. Both of these pieces of information provide access to sensitive data, so you don't want them falling into the wrong hands.
Secrets vs. sensitive information
You probably have other sensitive information you’d like to keep secret too, like PII (personally identifiable information). But they’re not secrets if they don’t directly grant you access to a system. While any sensitive information should be stored securely, the scope of our discussion here is limited to application secrets.
Secrets vs. configuration
Configuration is important because it influences how your application operates, but not all of it is really private. Your application needs to know what environment to run in: should it run in dev, or prod? That’s a piece of configuration, but it doesn’t authenticate or authorize you in any way—so it’s not a secret.
2.2 So what?
Secrets are the keys to your kingdom—yet they're constantly leaked
In 2019, researchers at the North Carolina State University scanned almost 13% of Github’s public repositories and found "not only is secret leakage pervasive–affecting over 100,000 repositories–but that thousands of new, unique secrets are leaked every day." [2] They noted it wasn't just inexperienced developers leaking secrets in hobby projects. Several large, prominent organizations were also leaking their secrets, including a popular website used by millions of college applicants in the US and a major government agency in Europe. In both cases, they exposed their respective AWS credentials. See for yourself how common it is.
Developers make honest but costly mistakes
According to the principle of least privilege, anyone working on your application should only have access only to the secrets they need to do their work. At the same time, if you’re on a small team, and you know everyone personally and trust their intentions, it’s tempting not to follow this principle. But sharing secrets freely is dangerous, because people make mistakes—over-privileging developers can lead to honest but costly mistakes. For example, in 2017 DigitalOcean discovered that their "primary database had been deleted" and as their web press release stated: “The root cause of this incident was an engineer-driven configuration error. A process performing automated testing was misconfigured using production credentials.” [3]
Malicious actors cause damage
Even if developers could be perfect, there are always bad actors out there, and mishandling your secrets can give attackers wrongful access to your secrets. In 2019, Capital One had a data breach that affected over 100 million individuals due to a vulnerability related to configuration secrets involving AWS S3 buckets. The attacker previously worked for AWS and was able to exploit a misconfigured firewall to extract files in a Capital One directory stored on AWS's servers. [4]
2.3 Common practices
Encryption
While encrypting a secret protects it from immediate threat, it isn’t a complete solution. For example, in a Rails application, the convention is to store your secrets in an encrypted secrets file. You can store the encryption key to unlock it in another file or in an environment variable, but that’s a secret too. And a particularly sensitive one: anyone who has access to it (and your application) can read and edit any of your secrets. So, you don’t want it to leak. But if you plan to secure it via encryption first, you’ll just kick the can down the road. This is an important problem we’ll revisit later.

Environment variables
The Twelve-Factor App methodology made popular the practice of storing configuration in environment variables to separate configuration from code. [5] Since secrets are often discussed in the context of configuration, it may feel natural to store your secrets in environment variables if you do so with your configuration. Environment variables aren’t bad, but it’s dangerous to depend on them to carry the weight of managing your secrets.
Sourcing environment variables from files
Environment variables are often set from files. For example, in
Node.js development, they’re set in a .env file and
then the contents of that file are loaded into the application’s
environment.


This has the advantage that you simply need to use a different
.env
file for production versus development environments. But if you
populate environment variables from files, you must ensure those files don’t get
accidentally checked into a public repository or otherwise leaked.
Plus, there's a glaring unanswered question: how are those
.env files distributed, and is that done securely?
Environment set as part of some other system
Some deployment and CI/CD tools provide a built-in way to set environment variables. Heroku, a popular Platform-as-a-Service, allows users to manually do so in a control panel. This is tedious and error-prone, and there is no fine-grained access control. A more general downside of letting your tools take care of it is how many different tools there are. Every time your team adopts a new one, developers have to stop and learn each new tool’s method for setting them, and each time they do, that’s a new opportunity for secrets to be mishandled.
The leaky environment
Regardless of how environment variables are set, they're leaky. Environment variables are implicitly made available to all children processes, so they're passed to anything the application calls. They’re often dumped in plaintext for debugging and error reporting, so the secrets stored within them can easily end up in logs.
2.4 Secrets in teams
Secrets get shared
Let's take a hypothetical team of four developers, and call them Alice, Bob, Charlie, and David. Suppose:
- Alice emails a config file containing secrets to Bob
- Bob Slacks a particular secret to Charlie
- Charlie accidentally checks it into version control
- David pulls that code and works off of it, and unintentionally writes code that later ends up logging that secret to a log file.
Their secrets are getting around. If you were on that team, would you know where your secrets are?
Maybe our hypothetical team tries to share secrets securely. Maybe Alice decides to take a screenshot of a secret and send that to Bob in Slack—and maybe she even goes back into Slack and deletes that screenshot once the recipient has got the secret. Or alternatively, maybe she puts that secret in a file and locks it with a password, sends the locked file over Slack and sends the password to Bob over some other communication channel, like email.
This still doesn’t look great. Without a system in place, you have to get creative to share your secrets securely, and that makes them even harder to track.
Teams change
Now suppose the following events occur:
- Alice quits
- Bob moves over from production to development
- New-hire Emily joins the team
When Alice quits, how do you ensure Alice doesn't retain her access to secrets? Does Bob still have production credentials? When Emily joins, does she have to ask around to find what secrets she needs?
Without a system in place, Emily may not get, in a complete and controlled manner, all the secrets she’ll need to do her work. She may not even know she needs some secrets until she gets to work, finds out she needs some, and has to hunt them down.
Secrets change
Let's add one more type of event to the mix, which will surely happen much more often than personnel changes:
- Charlie updates an API token
How do you ensure Charlie's teammates use the updated version? And what about applications that depend on it? The old token is invalid, so applications will crash if they try using it. Unless there’s some system for managing secrets sanely, Charlie may have to hunt down the people that need to know or the places where it needs to be updated, and hope that he got them all.
The security/productivity balancing act
While secrets are extremely sensitive, they must be accessible to you and your application.

There’s a tension between security and productivity, though, especially when it comes to sharing secrets with other developers. For example, how do you decide on and maintain access levels in your team? Then, how do you securely distribute credentials to team members who need them? And if someone leaves the team, how do you know which secrets they've accessed that you now have to update?
It may feel convenient to simply be able to access secrets at any time but if you don’t have structure, process, and security around your secrets, you’ll lose visibility and control over them. Eventually, you’ll find yourself with a big headache called secret sprawl.
2.5 The problem of Secret Sprawl
In all of the scenarios we just examined, we saw hints of secret sprawl. Secret sprawl is what you have when your secrets could be anywhere. Secret sprawl means your secrets are littered across your code, infrastructure, config, and communication channels.
The questions you can't answer
Secret sprawl means you can't answer questions like these with any degree of confidence:
- Who has access to what secrets?
- When was a particular secret shared or used?
- If you need to change a secret, where do you have to change it?
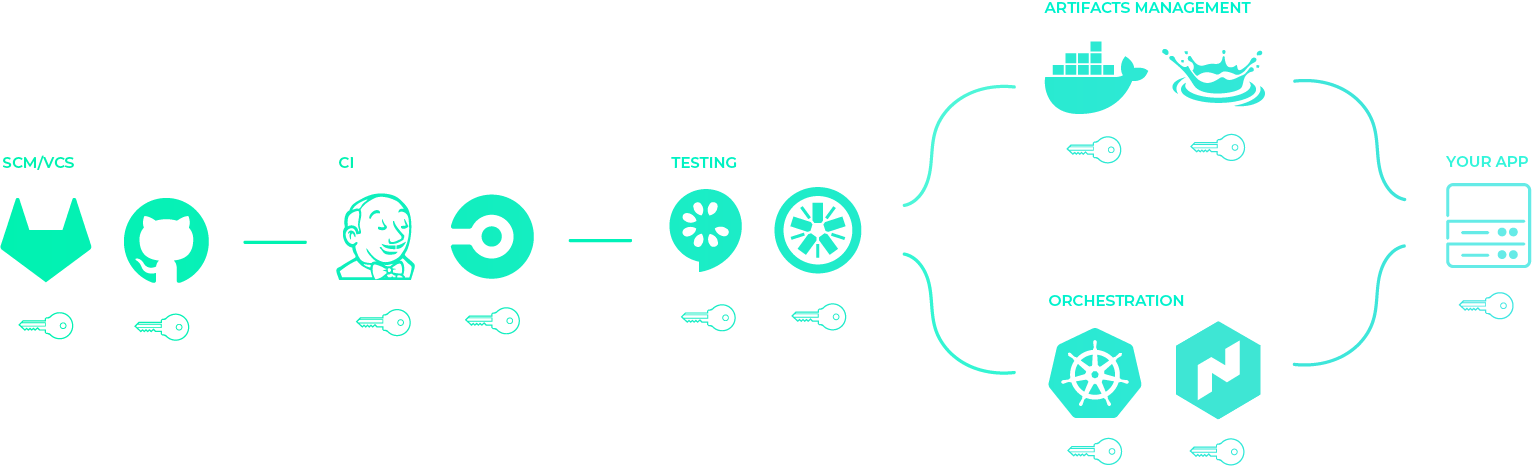
3 Secrets Managers
3.1 Centralization
To prevent secret sprawl, you must have a single source of truth—one place where all your secrets live. Establishing this "single source of truth" is centralization. Centralization tames secret sprawl, and paves the way to gaining visibility and control around your secrets.
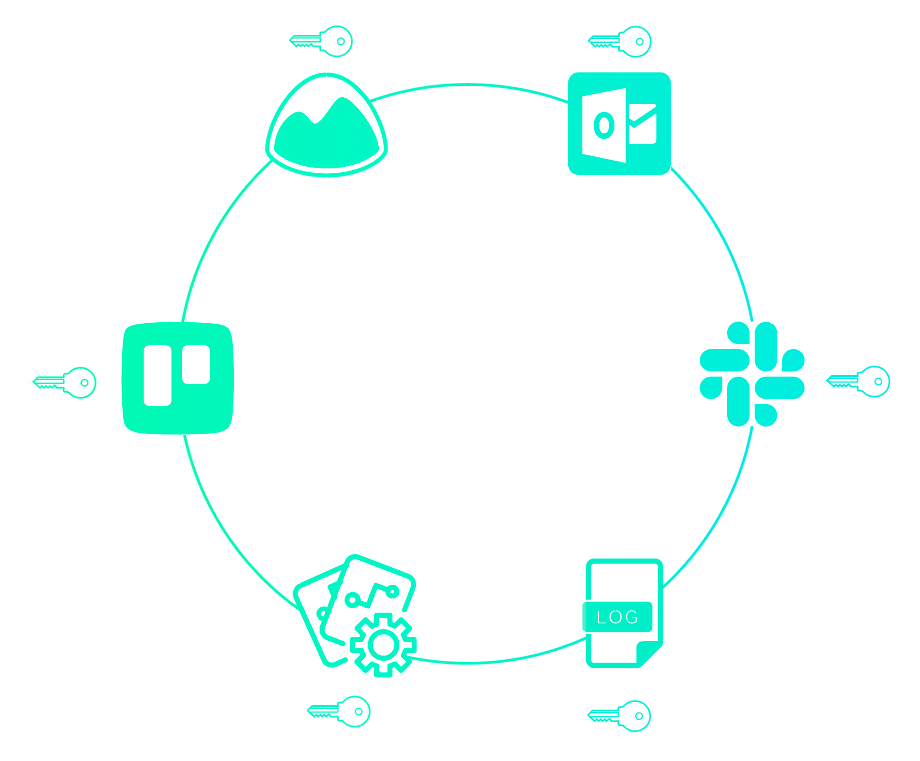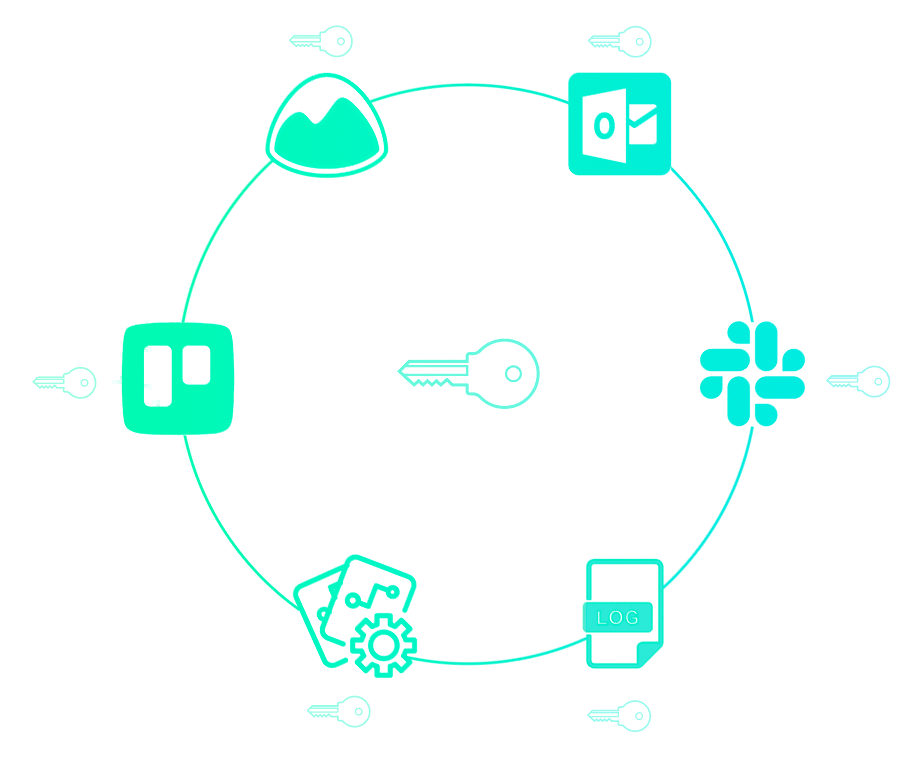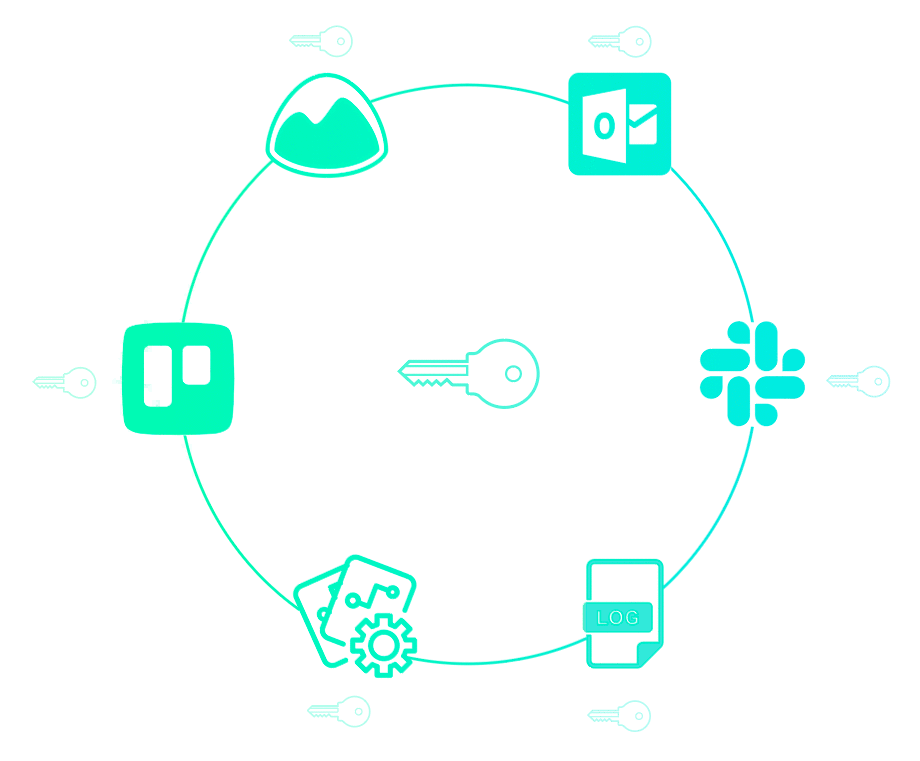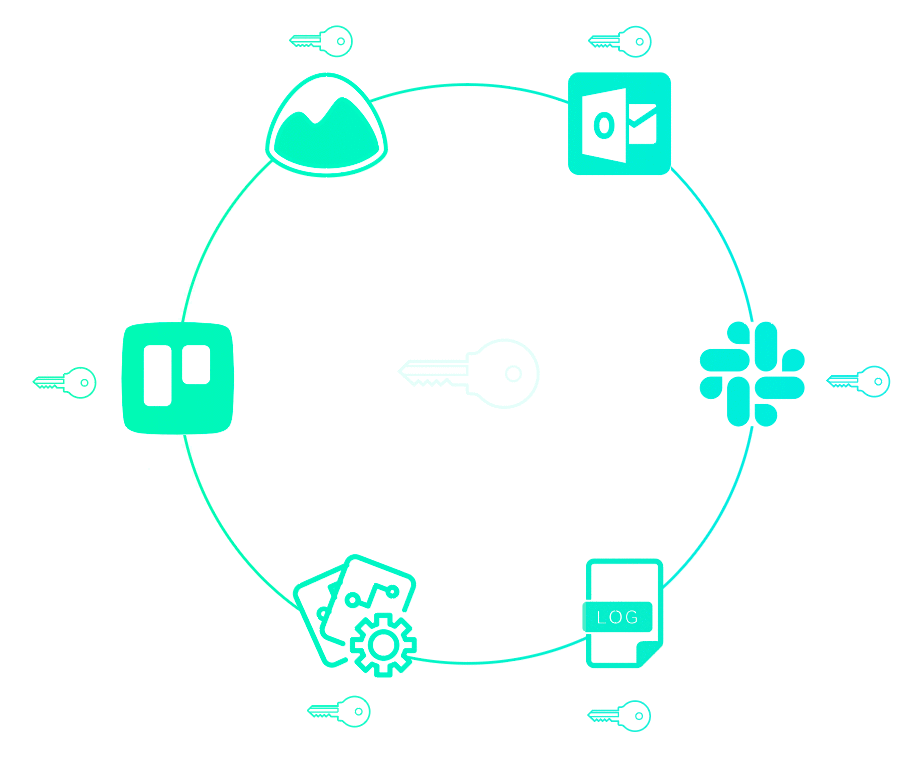
Previously, we showed that secrets might be sprawled across your infrastructure. Perhaps they are even passed down service-to-service in your pipeline. But you want it to look more like this:
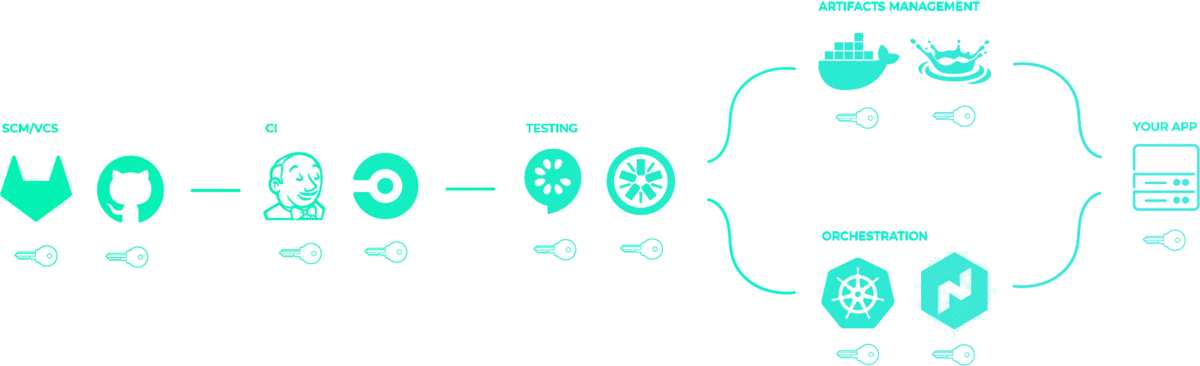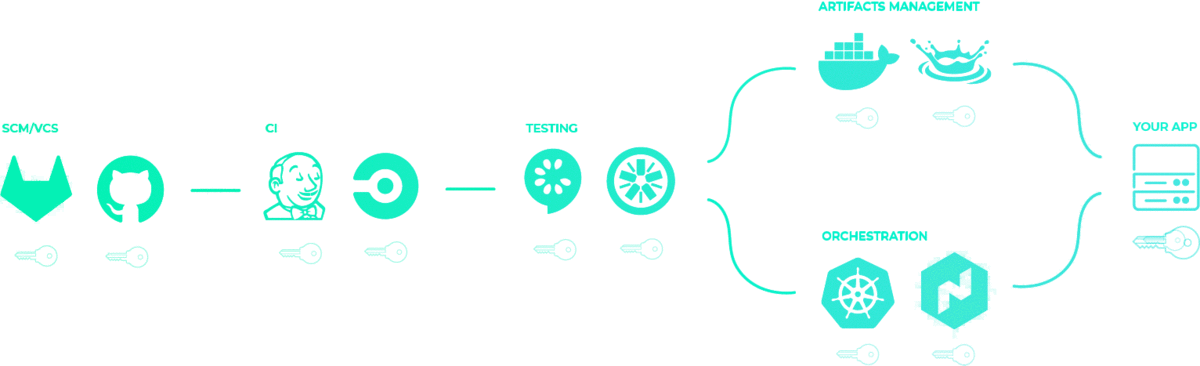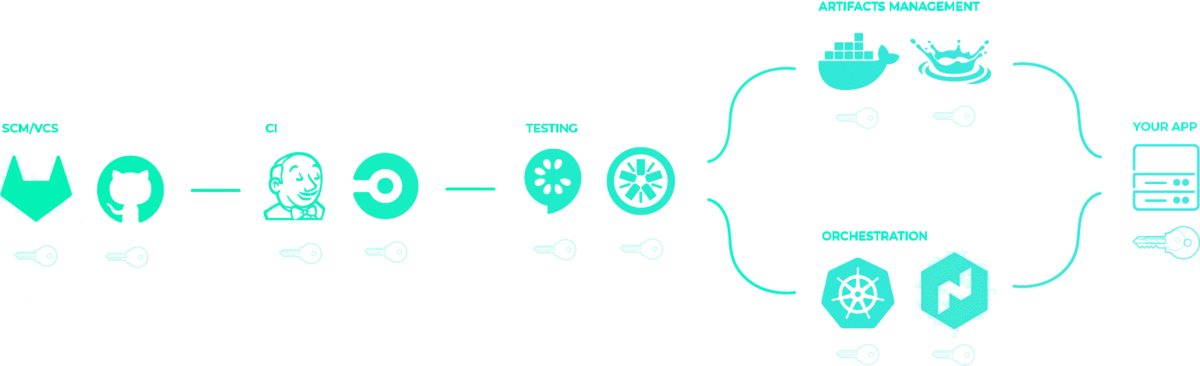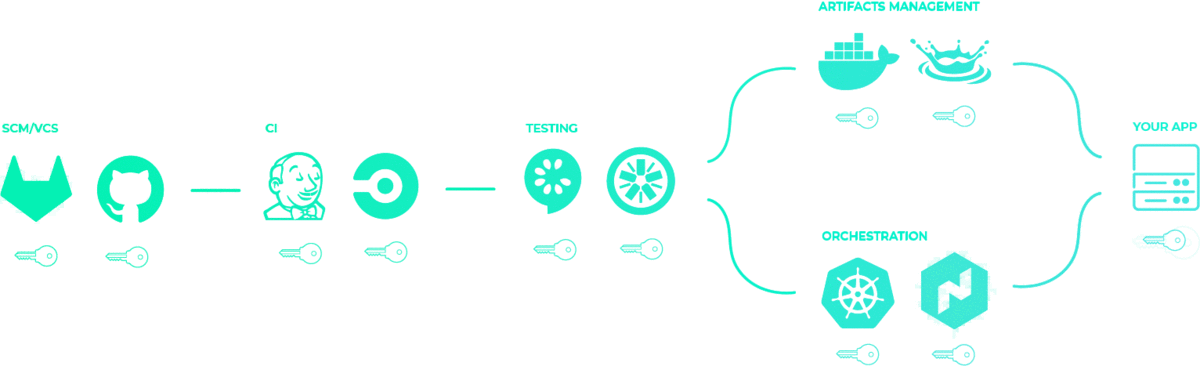
After centralization, only your app has secrets, or rather, whatever service needs secrets will get only the secrets they need. You thereby reduce the attack surface area of your application.
3.2 Encryption
In section 2.3, we mentioned that encryption alone isn't a complete solution. But when you combine it with centralization, you're well on the way. Your secrets should be encrypted client-side, meaning they never leave your device before they’re encrypted. They should remain encrypted in transit and at rest too, so they’re never seen nor persisted in plaintext. That includes encryption in communication channels, temporary stops, and persistent storage. Each step adds a layer of security, as illustrated below.
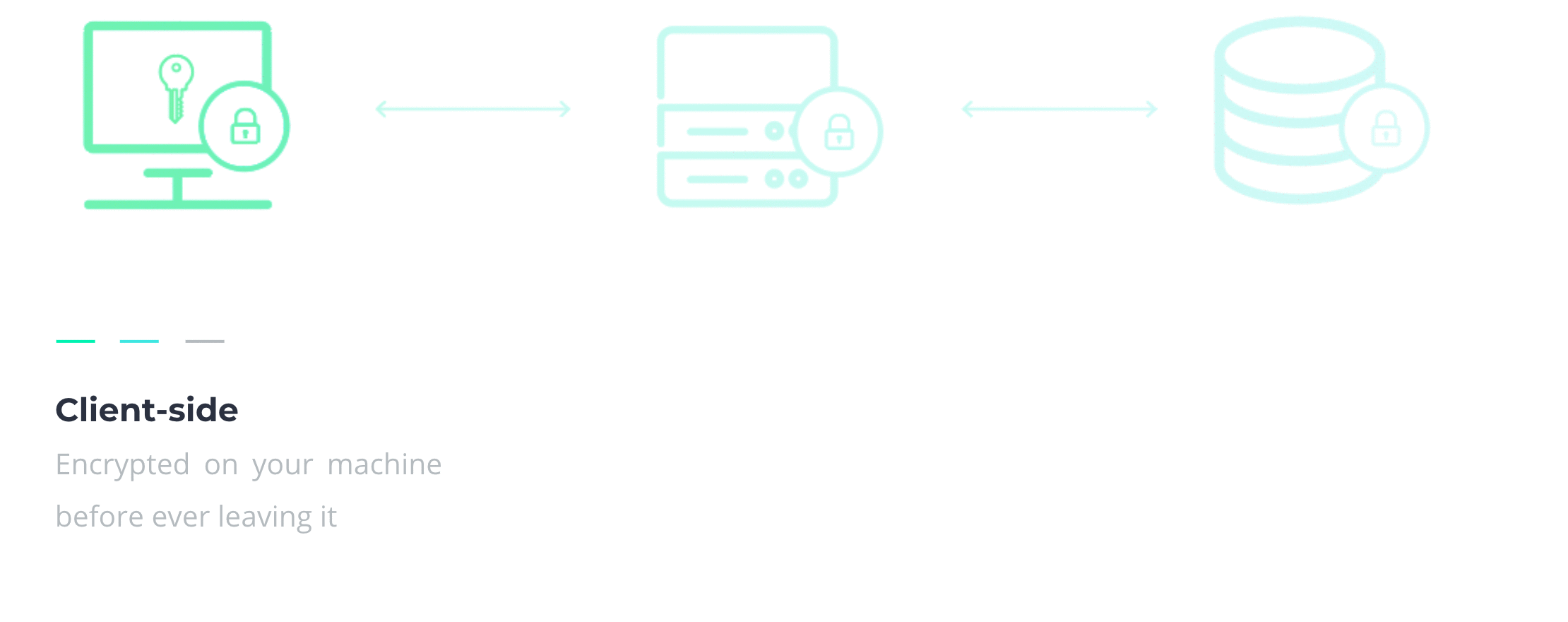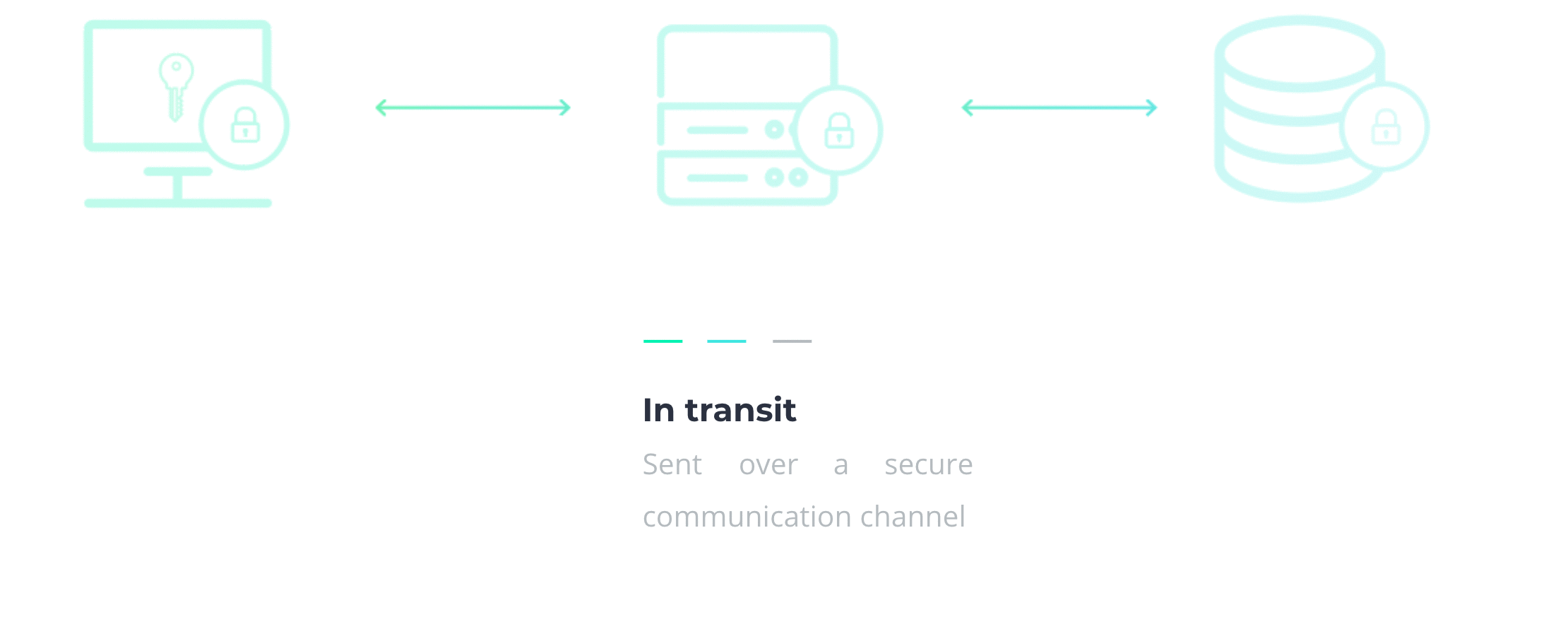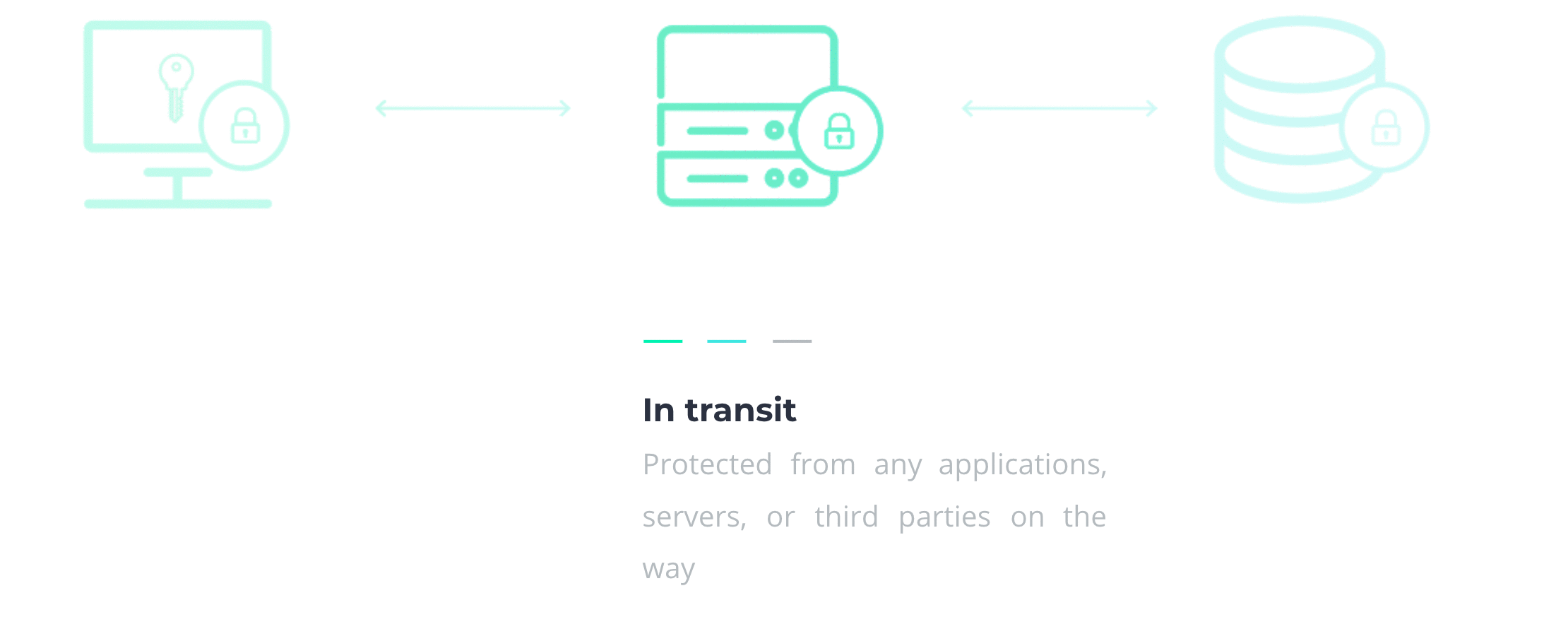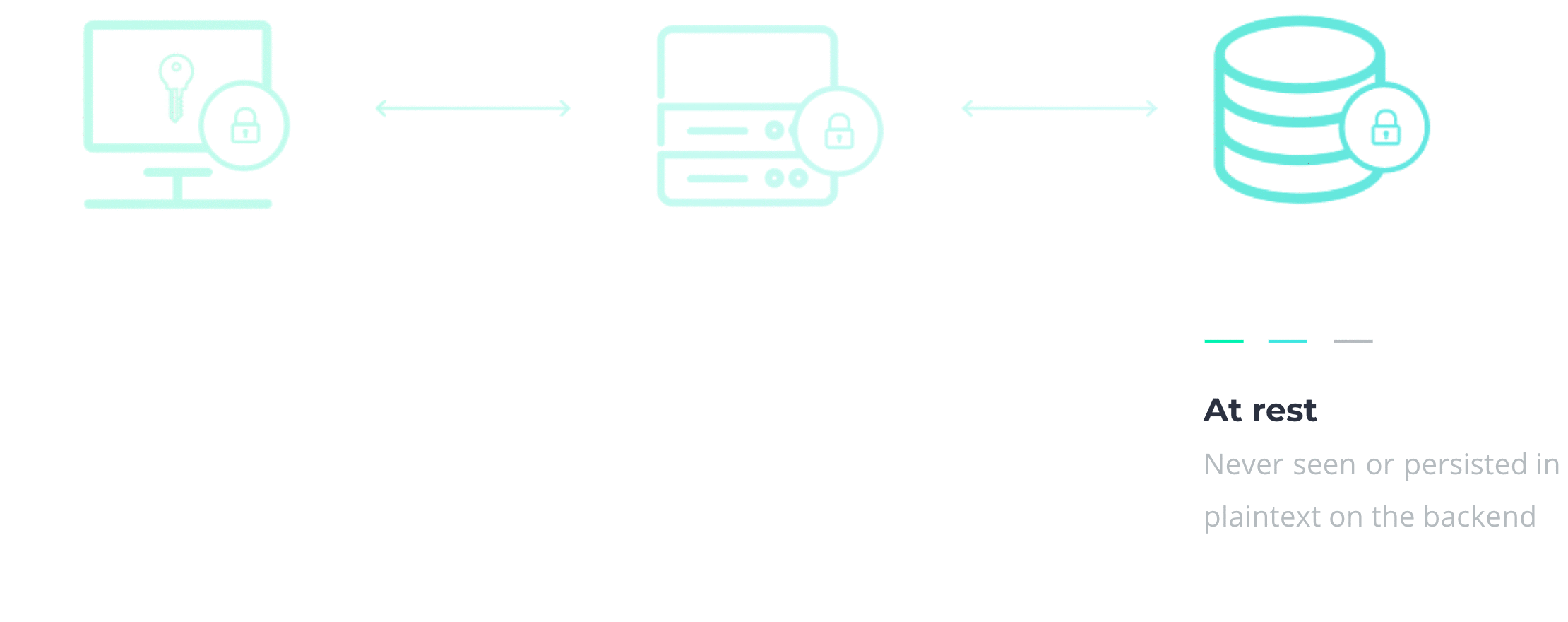
3.3 Secrets managers
A secrets manager is a system that helps you securely store and manage your secrets. Secrets managers are inherently centralized and invariably use encryption in some way. Beyond that, they vary in the use case they are targeted for and in the features they offer.
How to choose a secrets manager
In recent years, a number of secrets management solutions have popped up. There are several things to consider when you’re choosing a secrets manager. First, a secrets manager must keep your secrets safe. To do that, it should encrypt your secrets. Second, how does it accommodate multiple users? How does it let you share access safely? Third, you need to know how to actually use it in your applications. How do applications actually get secrets? You might have to significantly adjust your workflow depending on the solution you pick.
How secrets managers work with your application
Let’s zoom in on that last question: how applications get secrets. And that’s done in one of two ways: either your application has to fetch the secrets it needs—so you have to write more application code—or your application is run in a certain context such that it already has the secrets it needs.
- A secrets manager might require you to make an API call within your code to fetch secrets from it, in which case it’s more of a decoupled and passive component.
- On the other hand, your application might also be run with the secrets it needs already available. For example, if you use an orchestration service, such as Puppet or Docker Swarm, there will likely be a built-in way of specifying secrets, which will then be made available in the environment your application code executes in.
Another approach that works the second way is what the secrets manager SecretHub does. SecretHub runs your application as a child process and injects the secrets into the environment of that process. This gives SecretHub some level of control, as it can monitor the standard output and standard error streams of your application.
3.4 Existing solutions
Vault by Hashicorp
Vault is the most popular commercial solution. It's highly flexible and extensible. For example, it integrates with the storage backend and identity provider of your choice, and it can integrate with a broad array of plugins. But Vault is widely regarded as complex, and can be overkill for many teams. Their own docs admit this, stating "Vault is a complex system that has many different pieces." [6] It is probably the best choice if you need some of the features that only Vault offers, and if your team or organization has the expertise and bandwidth to manage the Vault beast.
Other commercial solutions
Although Vault is dominant, there are other players on the market.
- Doppler is an early YC startup that launched in late 2020 whose focus is making it "super easy" to manage secrets. One thing that may give users pause is that secrets are sent plaintext to Doppler.
- EnvKey has a different security model—it takes a "zero trust" approach and encrypts secrets client-side before they are sent over the network. Like Doppler, EnvKey is easy to get started with, but it is not as feature-rich: for example, it lacks secret versioning and the ability to segregate permissions on a per-project basis.
- SecretHub has client-side encryption and is feature-rich, but it is complex. SecretHub also redacts secrets from standard output and standard error, which helps to prevent secrets being visible in logs locally and/or in any logs that might be shipped off to third parties.
Ultimately, all commercial solutions are third parties that you have to trust. Many teams prefer using open-source software for a variety of reasons, and when it comes to secrets management, there is one strong reason to: you have full control over the system.
Open-source solutions
There are open-source solutions out there, ranging from utility-like tools that tend to require you do a lot to get up and running, to more complete solutions with UIs and built-in access control. The latter, though, tend to be targeted toward specific use cases. For example, Confidant, which was developed by Lyft in 2015, has a nice UI and intuitive access control, but it is Docker-centric and AWS-centric; it assumes you are using Docker and AWS roles for authorization. An example of a more utility-like tool is credstash, which, like Confidant, uses AWS under the hood. But it has limited functionality. For example, it doesn't offer logs or the ability to segregate secrets by project and environment. It also requires a fair bit of setup. For example, you need to have an AWS KMS key and your developers all need AWS credentials.
AWS Secrets Manager
AWS Secrets Manager came out in 2018, and if you're AWS-native, it may be perfect for your team. However, if your team doesn't already use AWS services, it's not exactly a plug-and-play solution. Navigating the AWS ecosystem presents a steep learning curve in itself, and Secrets Manager does not come with access control set up for you out of the box.
Summary of existing solutions
Existing solutions can be categorized in very broad strokes as ‘lightweight’, or ‘heavyweight’, where lightweight emphasizes ease of quickly getting started using it, and heavyweight emphasizes features.

Even in the lightweight category, there’s some diversity. For example Doppler emphasizes usability, while EnvKey emphasizes security. The heavyweight ones, such as SecretHub and Vault, tend to offer more features but at the cost of greater complexity. There are also several other open-source solutions, but they either have a lot of overhead or are built for a niche use case.
3.5 A new solution
While the solutions above provide some helpful ways to manage application secrets, we found they weren’t optimal for small teams to hit the ground running with. Because of this, we built Haven.

4 Introducing Haven
Haven is an open-source secrets manager built with small teams and ease of use in mind. It protects application secrets using best practices, plus it’s easy to integrate and use in your applications.
After we identified the components we’d need to build a good secrets manager, we realized AWS had trusted and long-standing services for some crucial components.
- Since secrets need to be encrypted and decrypted with an encryption key and "successful key management is critical to the security of a cryptosystem" (Wikipedia), we opted to use the highly vetted AWS Key Management Service (KMS). This is the only AWS service Haven uses that does not have a free tier: KMS costs $1 per month per key.
- Authentication and authorization is another crucial piece, and we chose AWS Identity and Access Management (IAM). Every time an entity makes a request to a non-public AWS resource, the request goes through IAM first. Using IAM as the gatekeeper for all storage and encryption logic meant that we could ensure only entities we authorized could read secrets, write secrets, and so on.
- Since we wanted IAM to be the gatekeeper for storage, we also use AWS for storage, and we had several storage options to choose from. Haven sits in the critical path of your application being served, so low latency and high availability were important. (On the other hand, scalability was not a concern for us.) We chose Amazon DynamoDB because it has good documentation, high availability, and single-digit-milliseconds latency.
Although we use AWS under the hood, you don't need cloud expertise to productively use Haven. The Haven Admin needs an AWS account—that’s it.
4.1 How does Haven work?
The architecture of a Haven instance can be split up into two components: the client side and the corresponding AWS infrastructure side. On the client side, each user—be it a Haven Admin, a developer or an application server—uses the Haven application to interact with the instance’s secrets. All of these users have Haven installed on their personal machines and are using Haven to interact with the same AWS infrastructure, albeit with varying levels of permissions.
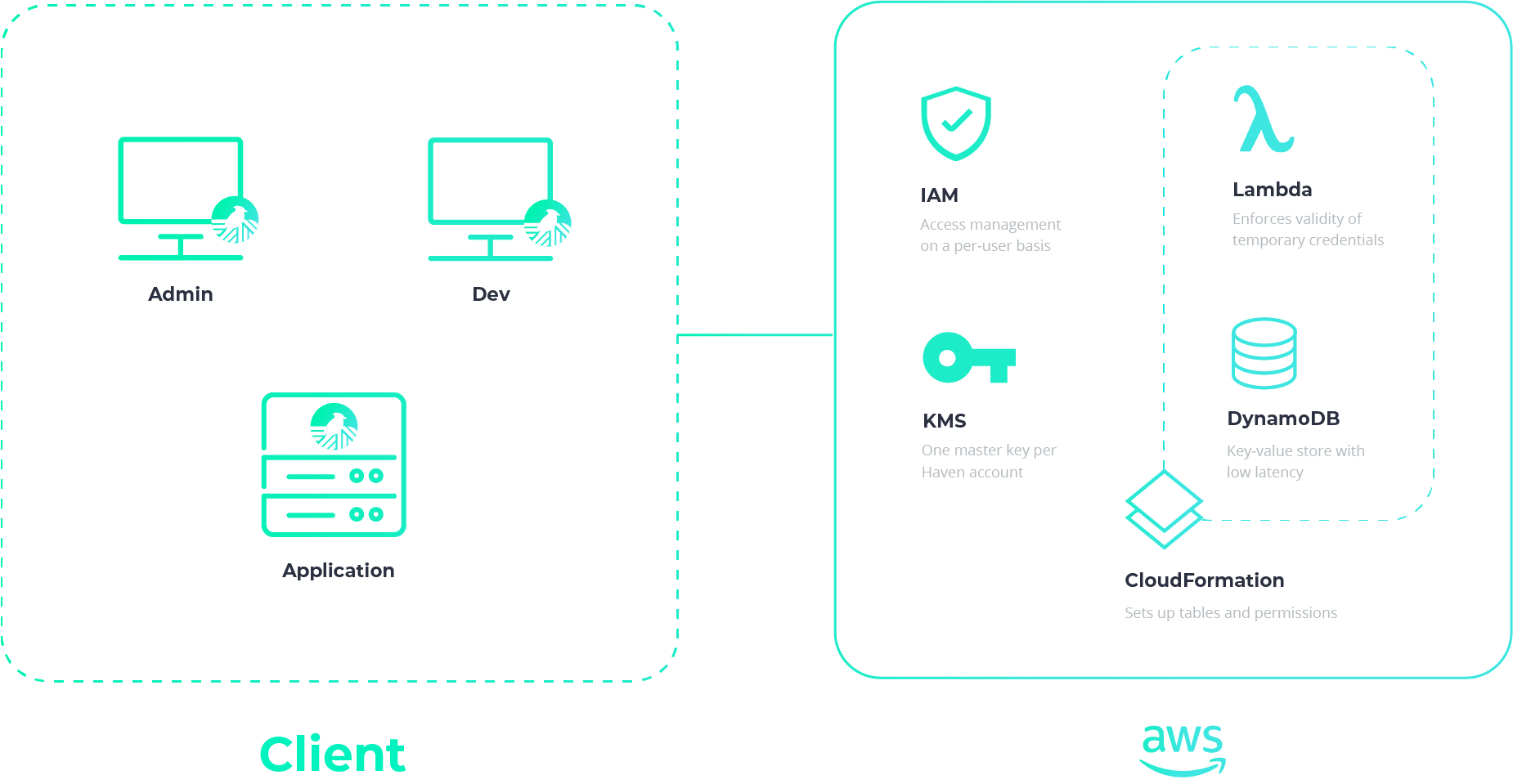
To showcase how Haven works, let’s walk through a common workflow, including how you set up Haven as an Admin, how you add a project to Haven, how you add developers to your Haven projects, and how you run your applications with Haven.
Setting up Haven
The Haven Admin is the person responsible for creating every project and every user, assigning permissions to the users, and reviewing access logs.
Haven offers both a UI and CLI, which share the same Haven Core
package under the hood. To get started with the Haven CLI, you
install the haven-secrets-cli package from npm. After installing the
npm package, you run haven setup, which assigns you as
a Haven Admin.
During setup, Haven connects to your AWS account and provisions the backend resources for creating projects and their environments, adding users, setting permissions, and adding and updating secrets. Note that your AWS account is the only place your secrets will ever be stored with Haven—there is no external Haven server with your secrets.
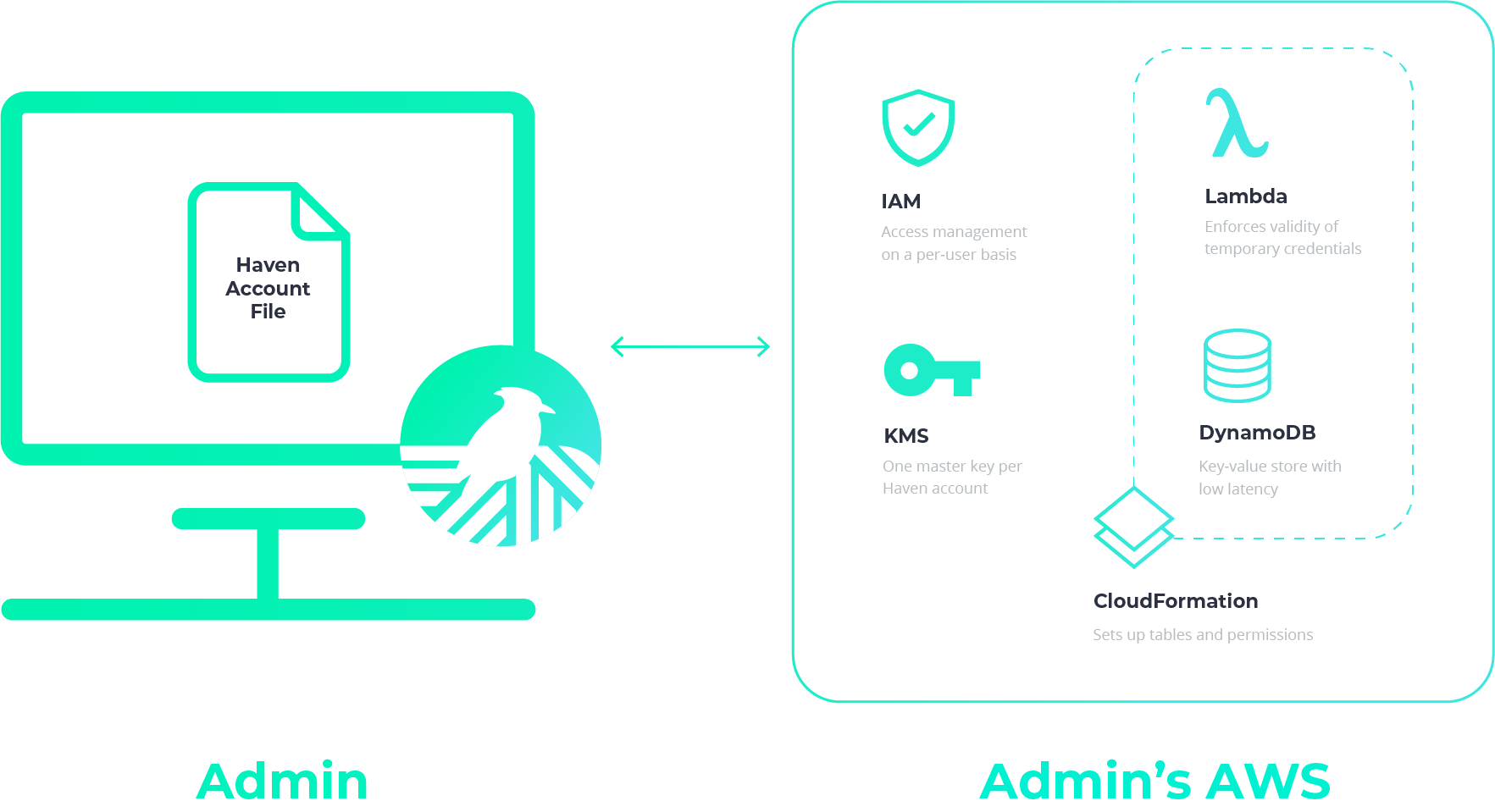
Haven provisions a file called havenAccountFile, which contains your Haven credentials. All you need to do is place this havenAccountFile in your home directory.
Integrating your projects
Let’s say you have an application called BlueJay that you want to
integrate with Haven. Note that as the Haven Admin, you are the only
person who will be able to create or delete projects. After you run
haven createProject BlueJay, Haven provisions a
DynamoDB table and set of IAM permission groups for your application
BlueJay.
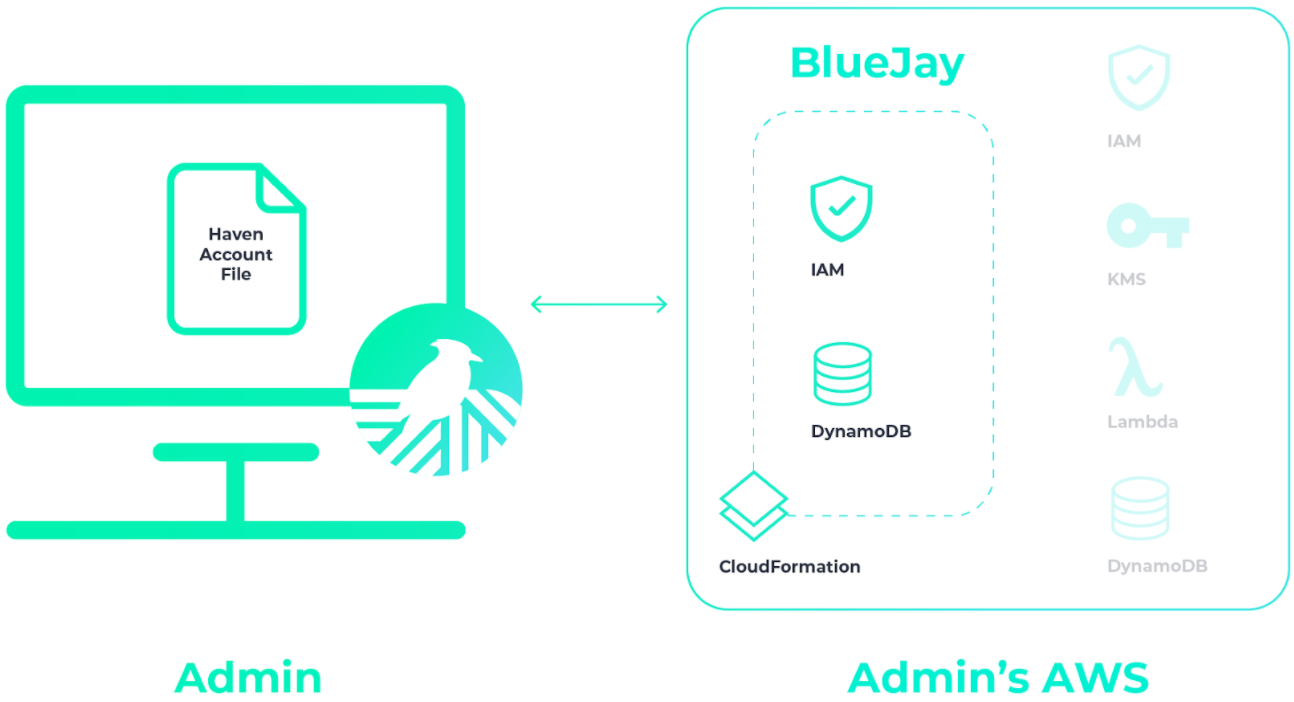
Next, you add all your secrets for the BlueJay project.
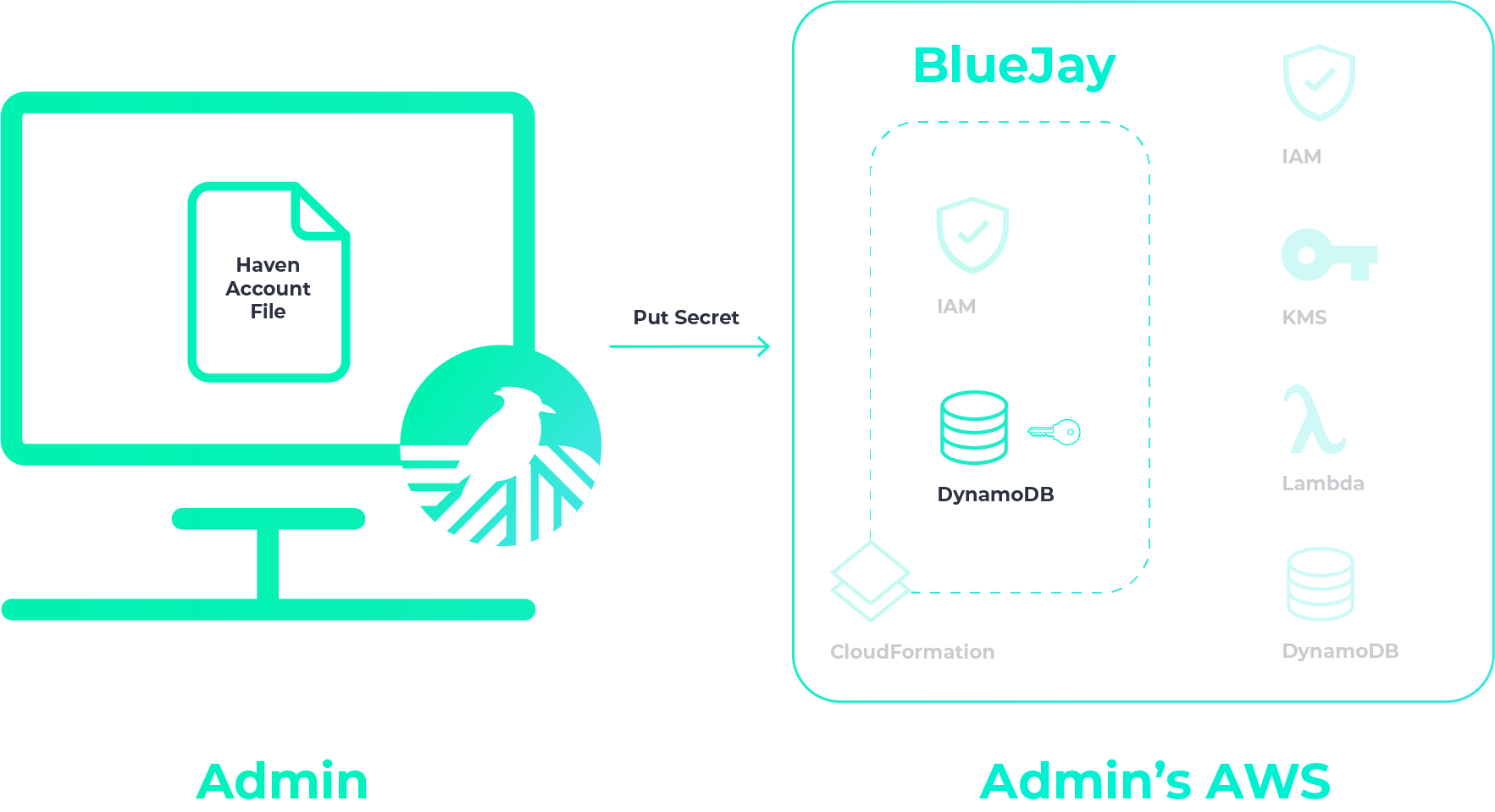
Your project BlueJay is now integrated with Haven.
Adding developers to Haven projects
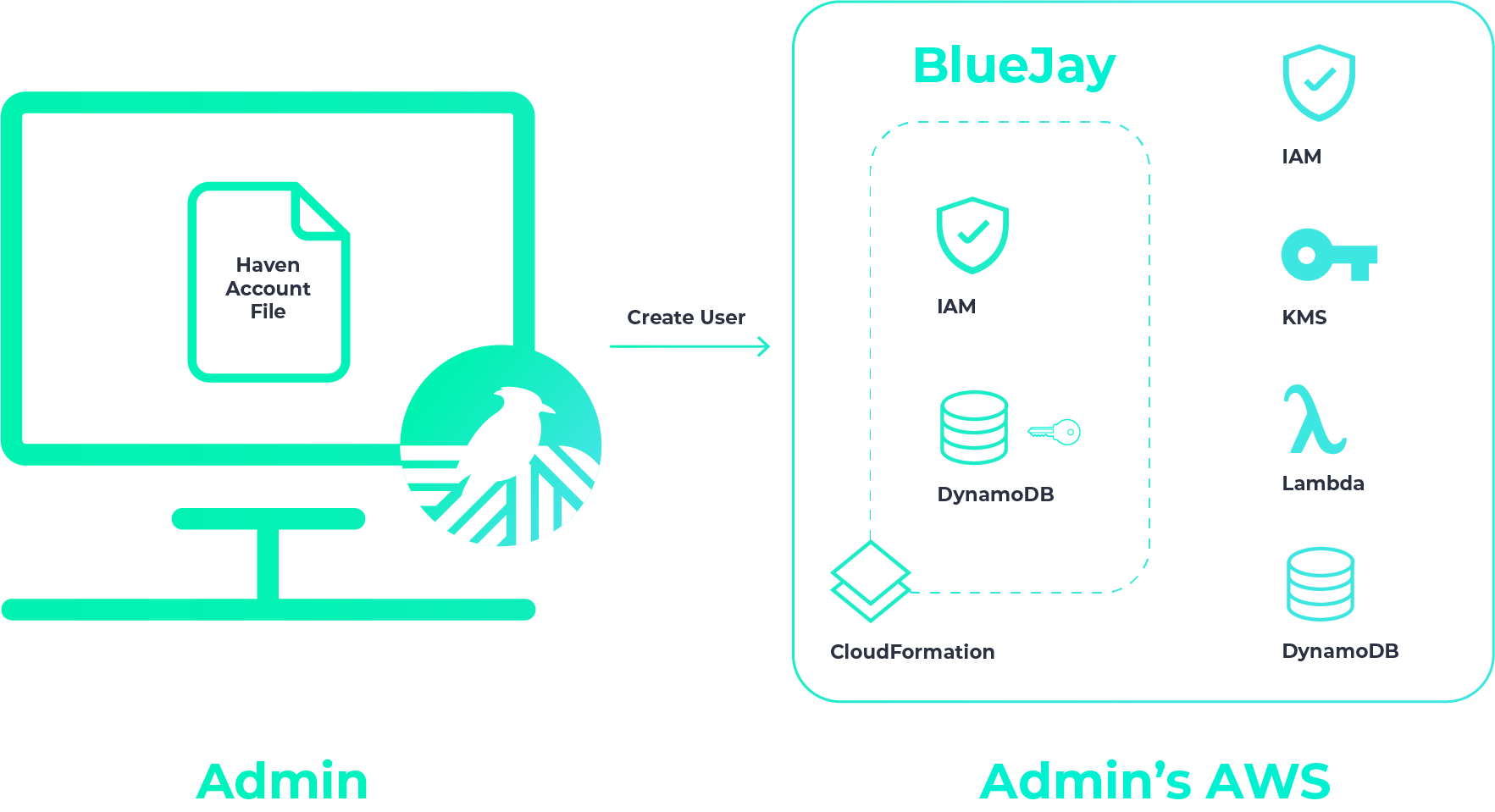
When you create a user, Haven provisions temporary user credentials. They’re saved to your computer, and you’ll then send this file to the intended user.
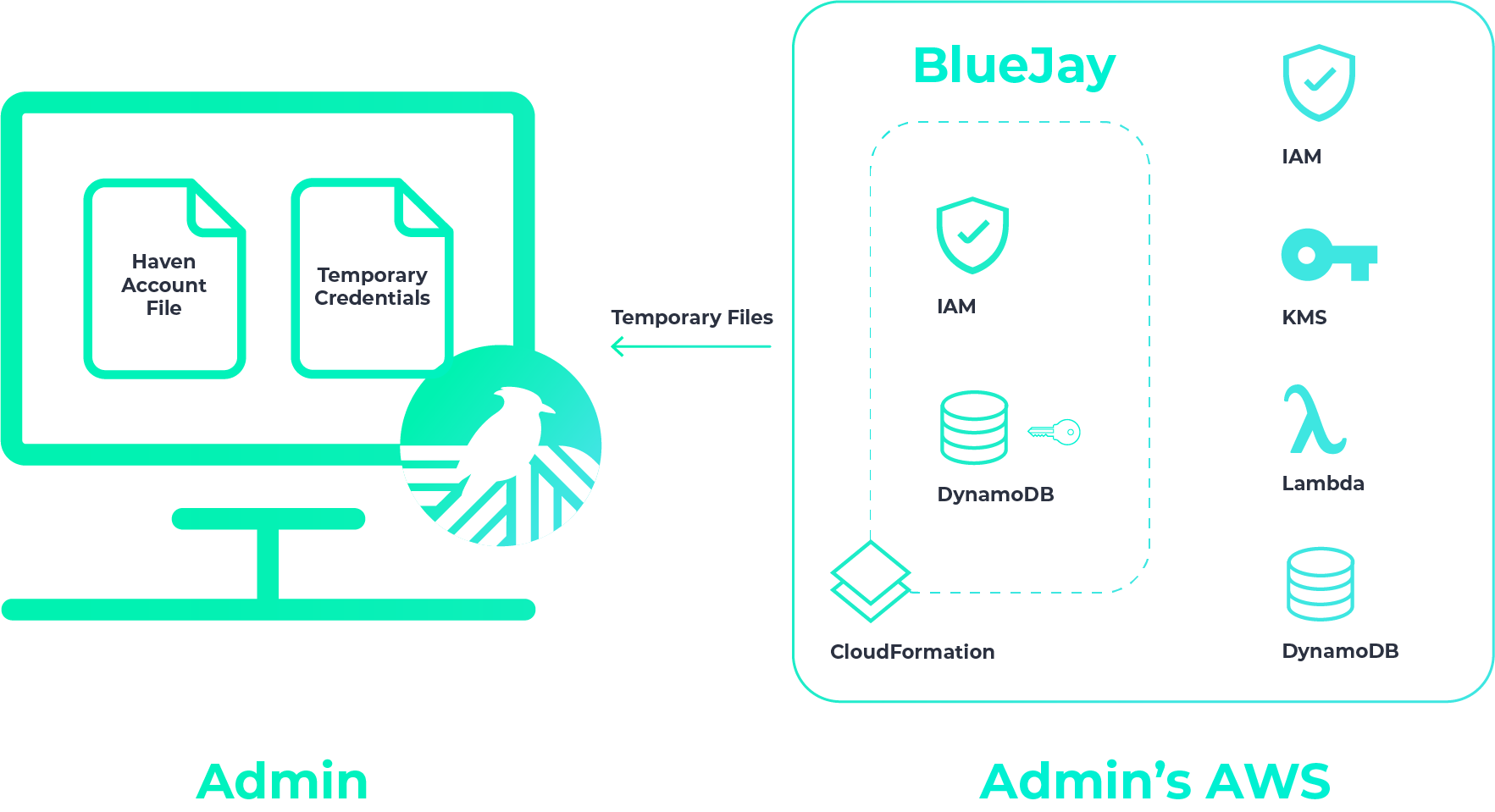
Each developer has to install the haven-secrets-cli package from npm on their personal computer. Let’s switch over to the new user’s point of view, where we see that they’ve received the temporary credentials.
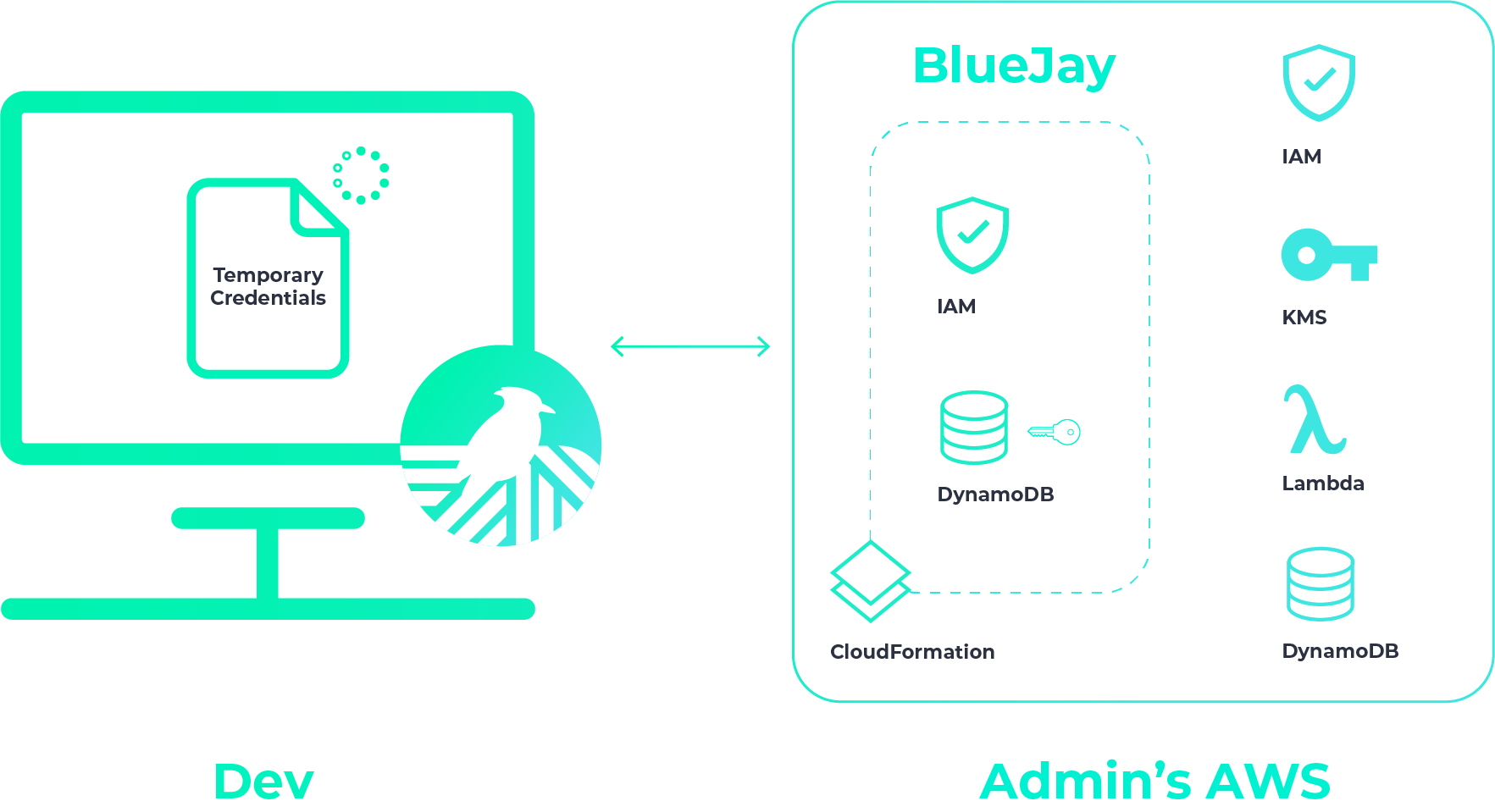
The developer puts this file in their home directory. Note that
Haven users other than the admin don't need an AWS account since
they'll be connecting to the Haven Admin’s AWS account. Initially,
the developer can’t interact with any projects and secrets. The
developer must run haven userSetup on their computer
after placing their havenAccountFile in their home directory. Haven
will then fetch their permanent credentials.
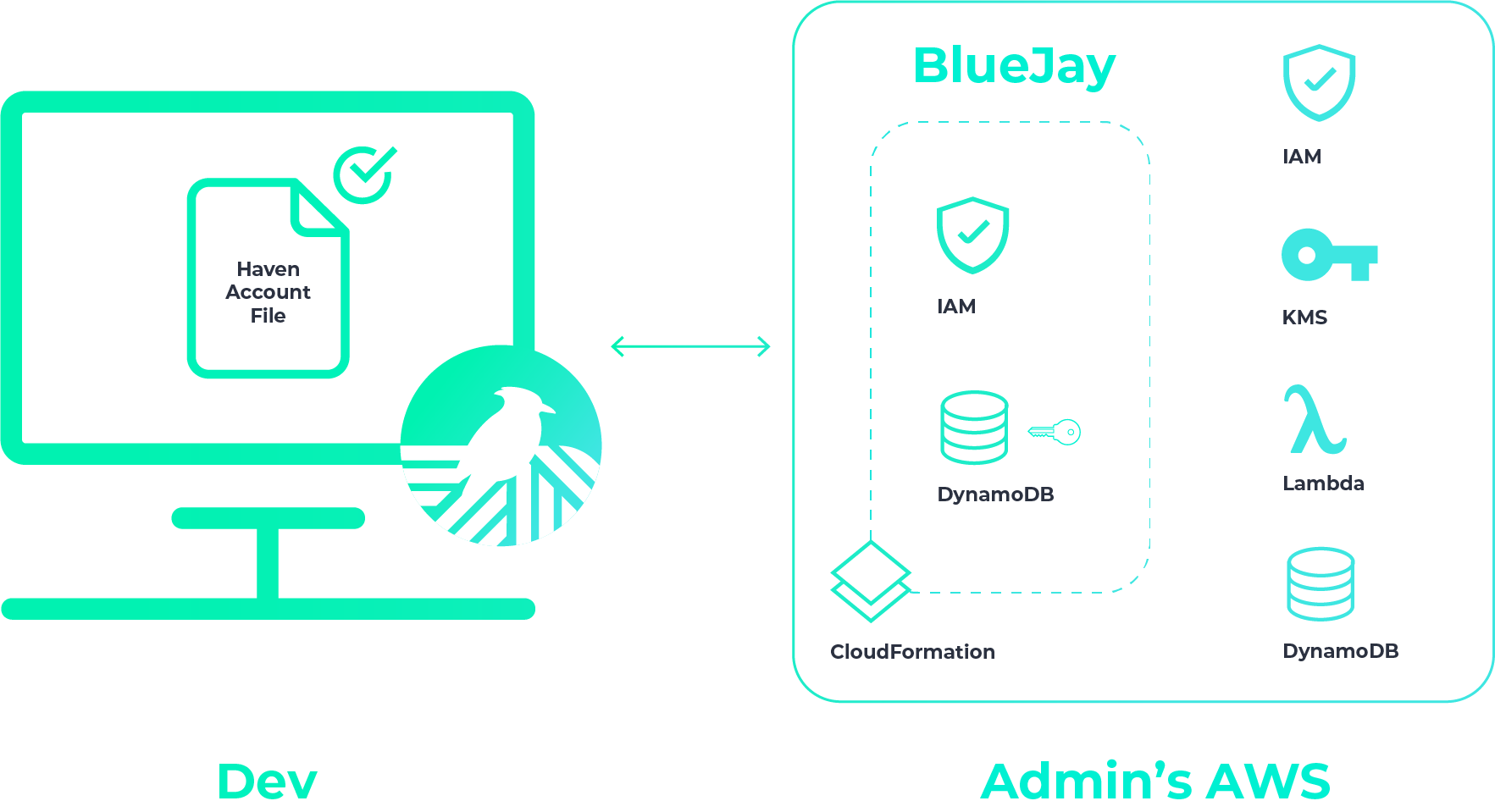
They are now able to start interacting with Haven based on the
permissions you give to them. You’re able to grant them read and/or
write permissions for secrets on a per-project, per-environment
basis. (Granting permissions is an admin-only capability.) Depending
on their permissions, they are able to create, update, and/or read
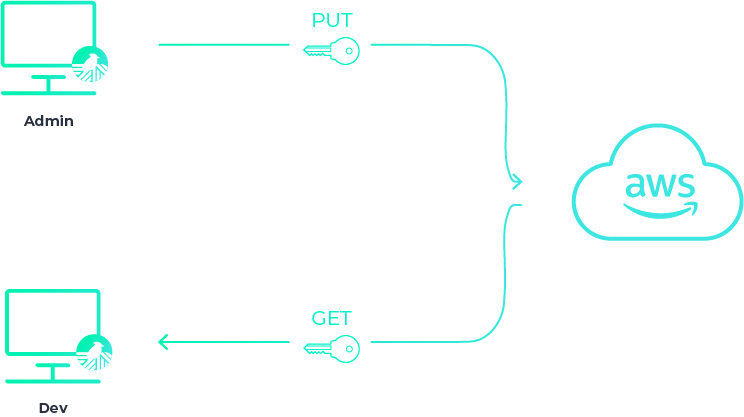
secrets, and also run the application locally using
haven run. Below, we depict the developer being able to
fetch a secret that you, the admin, has stored.
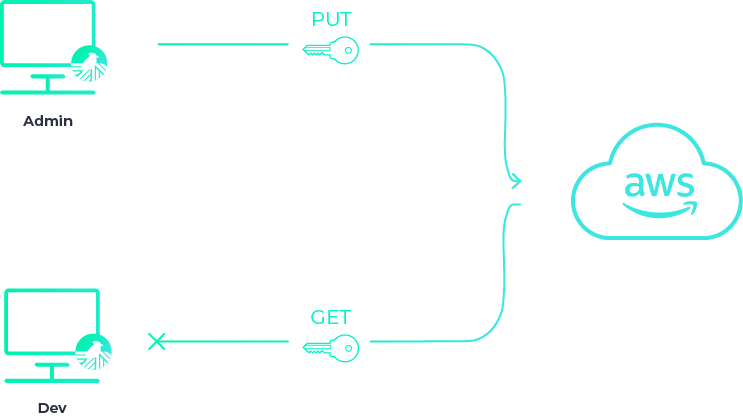
If the dev is not authorized to that particular secret, they’re denied access:
Using Haven in your application
Finally, let’s look at how you can use Haven in your applications.
We assume you run your application on a server, or rather, in an
environment that has a filesystem. The Haven Admin creates a “server
user” under this AWS account, which is really just another Haven
user like developers are. As we saw in the previous section, the
Haven Admin receives a havenAccountFile for the new server user. The
Haven Admin SSHs into the server where your application is run and
installs Haven globally or as a dependency in your project, as well
as place the havenAccountFile in the home directory of the
operating-system user that the application will run from. Then, the
Haven Admin will run haven userSetup, just as the
developer did in the previous section.
This server is now able to start interacting with Haven based on the
permissions you give it. You can run your application with
haven run.

5 Building Haven
In section 3.2, we noted that there are three questions you should ask about any secrets manager. The decisions we made and the challenges we faced in building Haven can be described pretty well by answering those questions:
- How does it keep your secrets safe?
- How does it let you share access safely?
- How do applications actually get secrets?
5.1 Keeping your secrets safe
Solving the “master key” problem
The very notion of encrypting your secrets has an inherent problem: what do you do with the encryption key? Assume you use symmetric encryption, so the encryption key both encrypts and decrypts your secrets. But then that encryption key is itself a secret—and a particularly sensitive one, since it can unlock all of your secrets. You might try to encrypt that key with another key, but that would be yet another key that you have to encrypt.
One way to solve this problem is to have a trusted third-party service store an encryption key that you don’t have physical access to. Instead, you dictate who has permissions to use it to perform encryption and decryption operations. For Haven, that trusted third-party service is the battle-tested AWS Key Management Service (KMS). We use KMS to store this key, which we’ll call a “master key”, and limit encryption/decryption access to it via AWS IAM policies. We don’t need to worry about safely storing this master key since AWS handles that. Now let’s see why “master key” is an appropriate name (hint: it decrypts other encryption keys).
Key wrapping
Key wrapping is an encryption best practice and refers to the technique of using two or more layers of keys to protect your data. It involves generating a unique data encryption key for each secret and encrypting the secret using that encryption key. Then the data encryption key is encrypted by the master encryption key. The encrypted key and encrypted secret are then stored until decrypted later. To decrypt your data, you perform this process in reverse: decrypting the data encryption key with the master key and then using the data encryption key to decrypt your secret data. Key wrapping is also sometimes called envelope encryption.
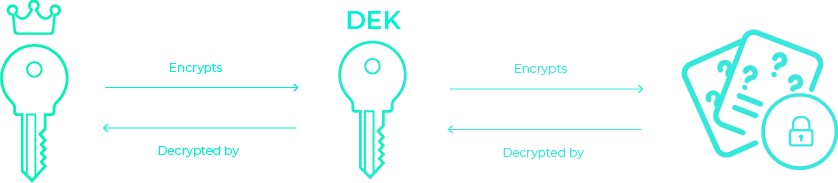
Key wrapping has two advantages: first, it’s harder to brute force the encrypted data since each is encrypted using a different key; second, you reduce the attack surface area, because the master key never sees your plaintext data—only plaintext data encryption keys—so an attacker would need access to both your secrets storage and the master key (and in addition, there’s one less instance of your plaintext secrets traveling along the wire). You may be wondering what you do with these encrypted data encryption keys: you store them alongside the encrypted secret itself, often in the same database row.
Implementing encryption best practices
It's a common saying in software that you shouldn't "roll your own crypto"—you should use a vetted cryptographic library. We use the AWS Encryption SDK, a client-side encryption library, because it adheres to cryptography best practices like key wrapping. The AWS Encryption SDK requires a master key, so Haven uses the master key in AWS KMS that it creates for you in initial setup.
Haven follows the best practices of encrypting your secrets client-side, in transit, and at rest. When you add or update a secret, it's first encrypted on the client using the SDK and then sent encrypted in transit via TLS to be stored on Amazon DynamoDB, where it is encrypted at rest.
Our encryption scheme as a whole
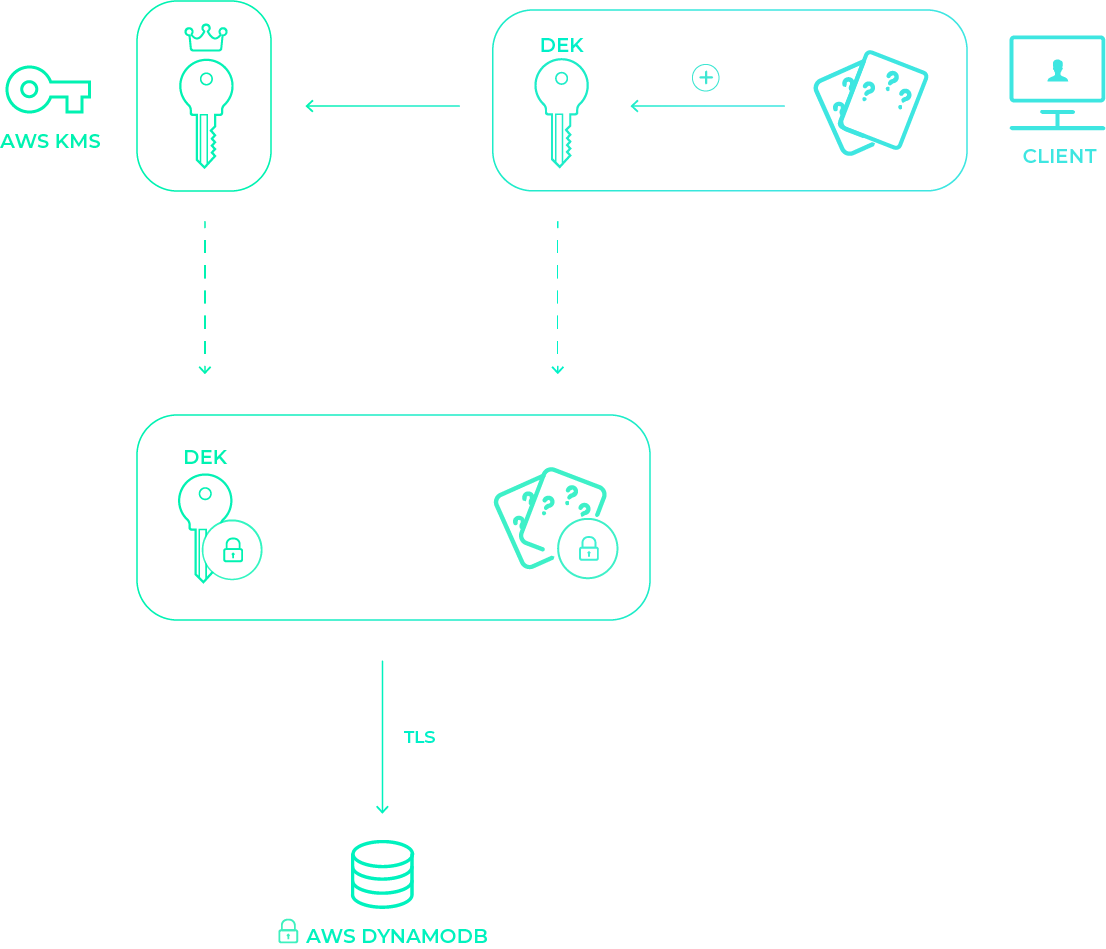
The diagram above shows Haven’s encryption scheme from start to finish. First, to encrypt a datum, a unique data encryption key is generated and is used to encrypt the secret on the client side as seen in the top right. Then, as shown in the top left, that data encryption key is encrypted using the singular master key stored in KMS. Both of these encrypted pieces of information are encrypted in transit via TLS and sent to DynamoDB to be stored alongside each other as shown in the bottom of the diagram. Thus we can see that Haven encrypts your data client side, in transit and at rest up on DynamoDB.
Storing and fetching secrets
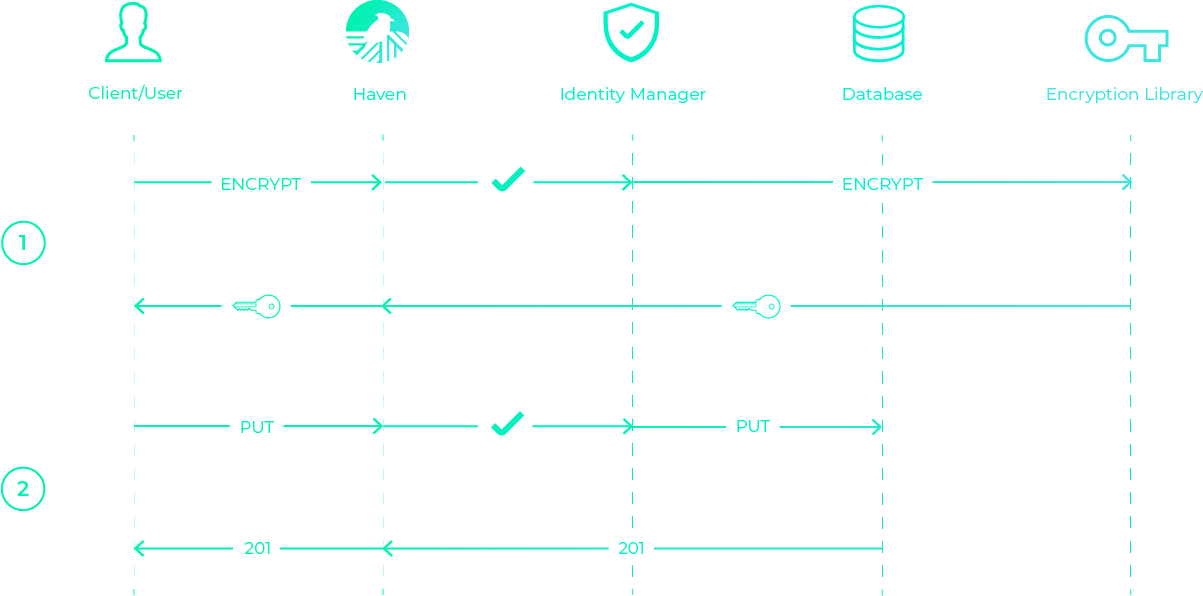
As we see below, Haven first makes a request to the AWS encryption SDK library to encrypt a secret. The SDK checks that the caller has the IAM permission to encrypt, and if so, generates a data encryption key, encrypts the secret value with it, and then encrypts the data encryption key with the master key. Then, Haven takes this encrypted data, and (if the user has permission) stores it in the database. Haven also stores the secret’s name, version number and whether the secret is flagged, in that same row.
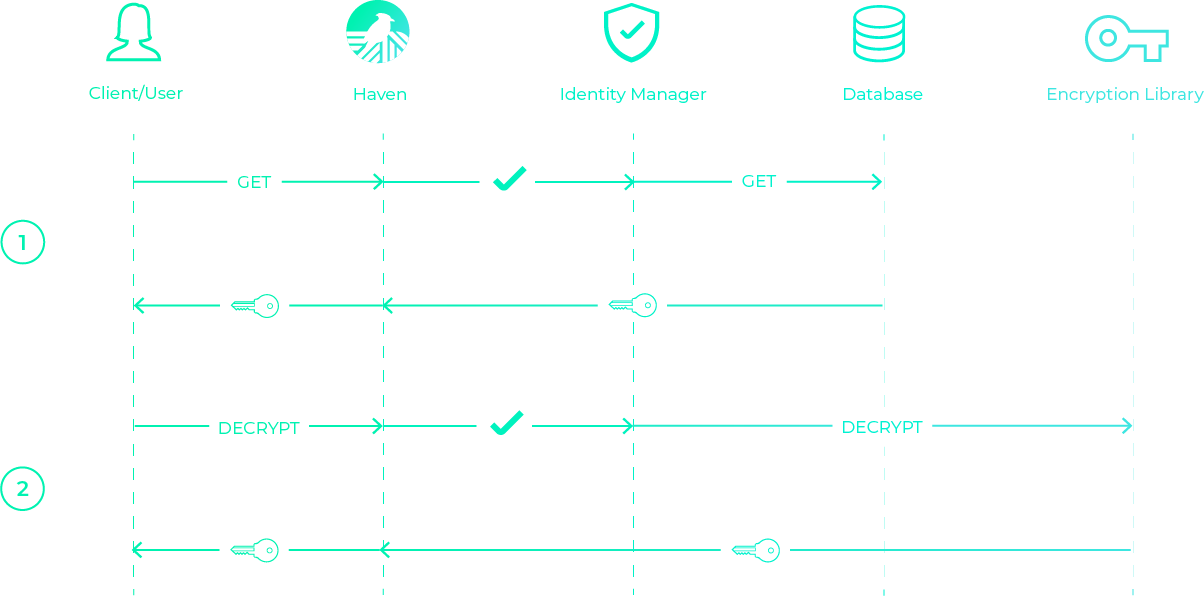
When you fetch a secret, Haven first fetches the encrypted secret from the database, then decrypts it using the Encryption SDK.
Running the UI web application on localhost
We chose to run the Admin/Developer UI Dashboard from localhost in order to avoid the security issues that any application running on the public web faces. [7] We were inspired by EnvKey, whose FAQ states:
Unfortunately, it's still not possible to implement true zero-knowledge end-to-end encryption on the web. Apart from a fundamental chicken-and-egg problem when it comes to server trust, there's no way to protect against all those ever-so-convenient browser extensions that so many folks have given full-page permissions. [8]
A second reason we run the UI app locally is to make it clear that Haven does not have a backend “Haven” server, so we could not snoop on your secrets even if we wanted to.
5.2 Sharing access safely
Supporting multi-project teams with fine-grained permissions
Enforcing the principle of least privilege is important, and Haven makes this easy by limiting access along three dimensions: by project, environment, and by action, where an action is read-only or read-write.
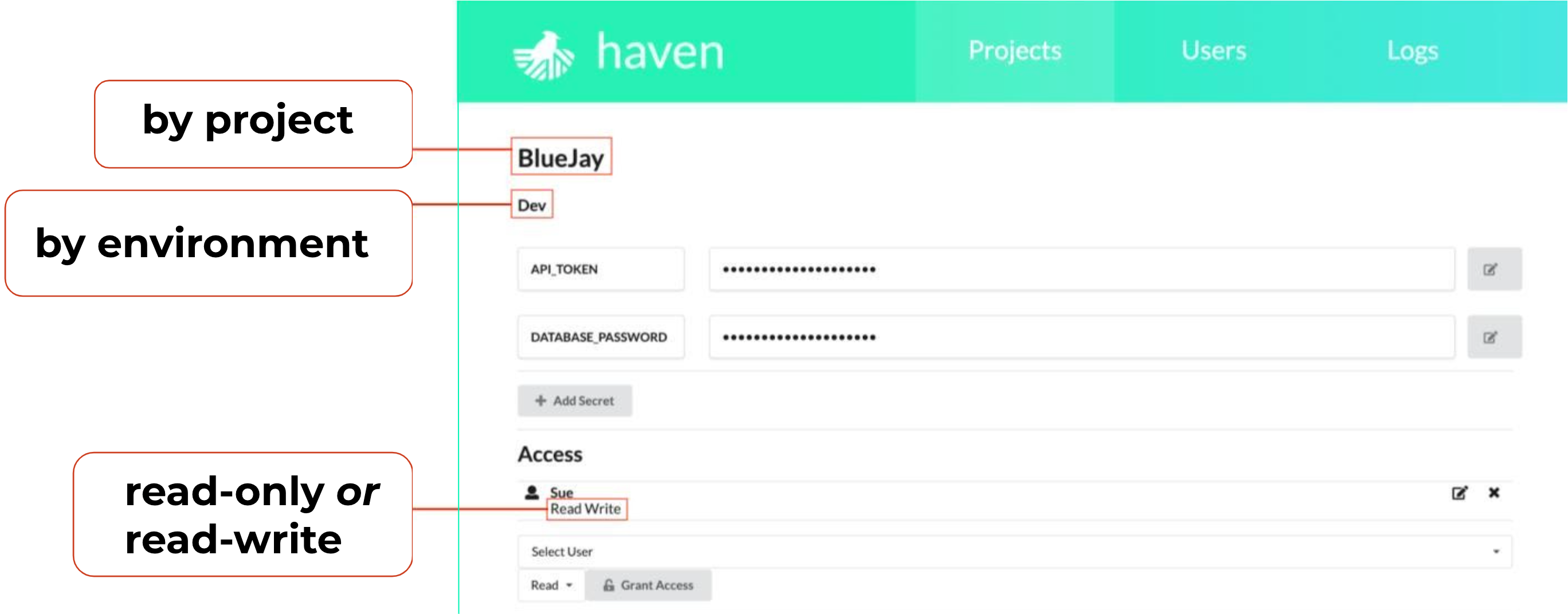
Above, we see Sue has read-write access to secrets for project BlueJay in the Dev environment.
Mitigating the "initial credentials" problem
Creating credentials for a new Haven user means creating a new secret. After all, those Haven credentials may permit the ability to read and write secrets! So, how can we ensure that we don't cause our own secret sprawl?
Temporary credentials
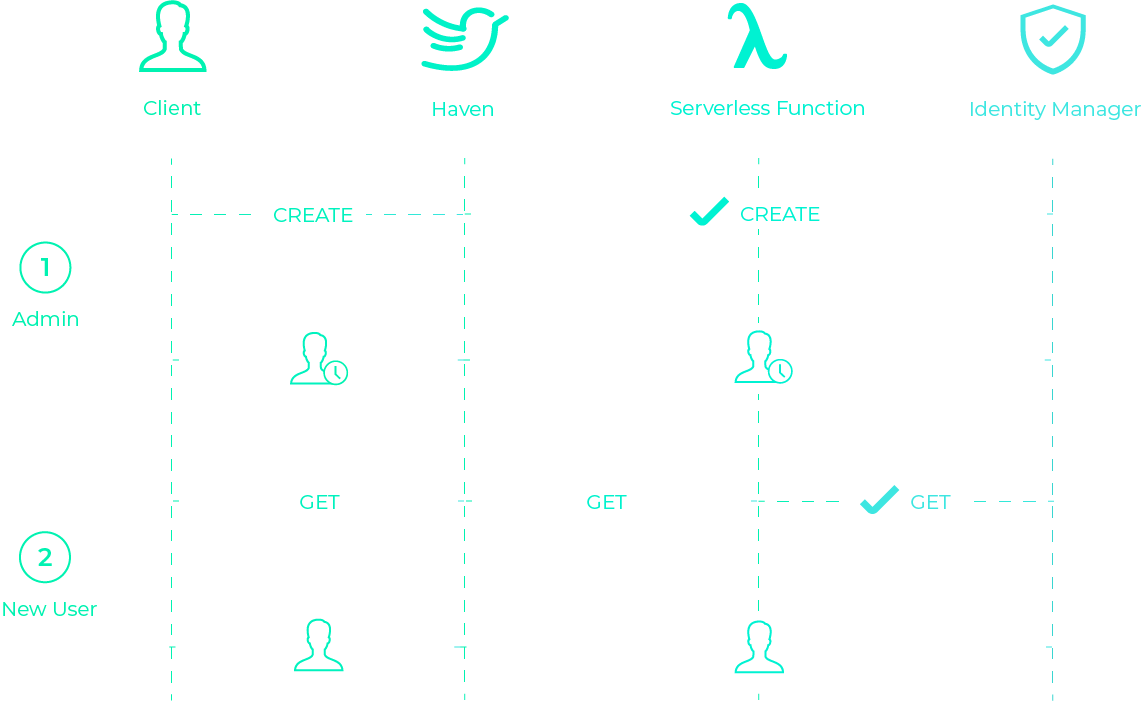
Our solution was to create temporary credentials good for only one hour. The credentials don’t have permissions to do anything except request permanent credentials, so the user must ‘change their password’ before they can do anything else. We use an AWS Lambda function to enforce the one-hour limit. If someone doesn’t use their temporary credentials within an hour, the Haven Admin will need to create a new user.
The flow is illustrated below: first, the Haven Admin adds a user,
either in the UI or the CLI, then Haven downloads a file with
temporary credentials and the Haven Admin sends this to the new
user. Second, the new user places the Haven file in their home
directory and runs haven userSetup. Haven invokes a
lambda using those temporary credentials, the lambda checks if
they’re still valid, and if so, returns permanent credentials which
Haven then puts into the user’s haven file. At this point, the new
user would need to tell the Haven Admin that they set up their
account, so that the Haven Admin could add them to projects and
environments.
Revocation of permissions and flagging of secrets
The Haven Admin can easily revoke any permission for any user or even delete users. When a user's permission to some secrets is revoked, the secrets are automatically flagged, and the next time the Haven Admin or a developer uses the UI Dashboard, they will see a red flag next to the secret, indicating they should rotate (change) that secret.
5.3 Getting secrets to your applications
Getting secrets to your application should not itself contribute to your secret sprawl, and it should be as easy as possible to do. We settled on an approach similar to what the existing secrets manager SecretHub does.
Secrets injection
SecretHub is a complex secrets manager and there are many ways of using it, but in one way of using SecretHub with your application, SecretHub runs your application as a child process and injects the application’s secrets into that child process as environment variables. [9]
Haven works the same way. This has three benefits. First, your
application’s secrets aren't stored in a file somewhere on the
application server (so no secret sprawl in that regard). Second, due
to the nature of child processes, Haven can redact any secrets
leaking out on standard output or standard error (we explain how shortly). Finally,
this approach makes it easy for the developer: they can simply
install the Haven package and change their application’s start
command to include haven run.
Why environment variables?
There are pros and cons of using environment variables. A weakness of environment variables is the environment can get leaked or inherited: a logging or debugging tool may dump the environment, or a malicious child process may inherit and read your secrets. [10] But environment variables do have one major security advantage: they die when their process dies. Any environment variables you set for that application are for that process and will disappear once your application stops running—leaving no trace behind, unlike a file. Besides the security advantage, environment variables also have two major pragmatic advantages: 1) they’re language and OS agnostic, and 2) many developers are familiar with them.
When we surveyed existing solutions, we noticed that most dedicated secrets managers either permit you to store secrets in environment variables if you want to (e.g. Vault) or just always put secrets into environment variables (e.g. EnvKey). And outside of dedicated secrets managers, if you're using Docker's or Kubernetes's built-in ways of handling secrets, you'll be setting them as environment variables. Since centralization and encryption are arguably far more important for security than whether you use environment variables, and since using them is standard, we decided to use environment variables.
Redacting secrets from an application's standard output and standard error
We wanted to mitigate that risk of environment variables showing up in logs from processes that dump the whole environment. We did so by spawning your application as a child process.
Spawning a child process
A process can simply be thought of as a running program. When you
run your application, it runs in a process. The Node.js runtime allows spinning out sub-processes called "child" processes, and Haven uses the spawn method from Node's built-in child_process library. When using the spawn method, you specify the
program you want to run and that program is run as a child process.
The standard I/O of the child process is piped to and from the parent
process: standard input is piped in to the child from the parent, and standard output
and standard error are piped out from the child to the parent.
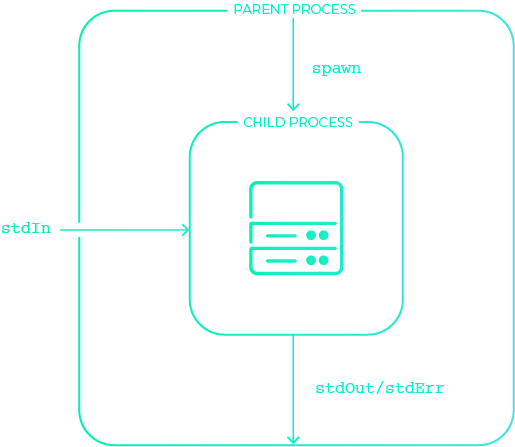
This is what allows us to provide a simple wrapper for your application, making for an easy-to-use secrets manager, as well as what lets us intercept any logging of secrets on standard output and standard error and redact them for extra security.
How it works with your application
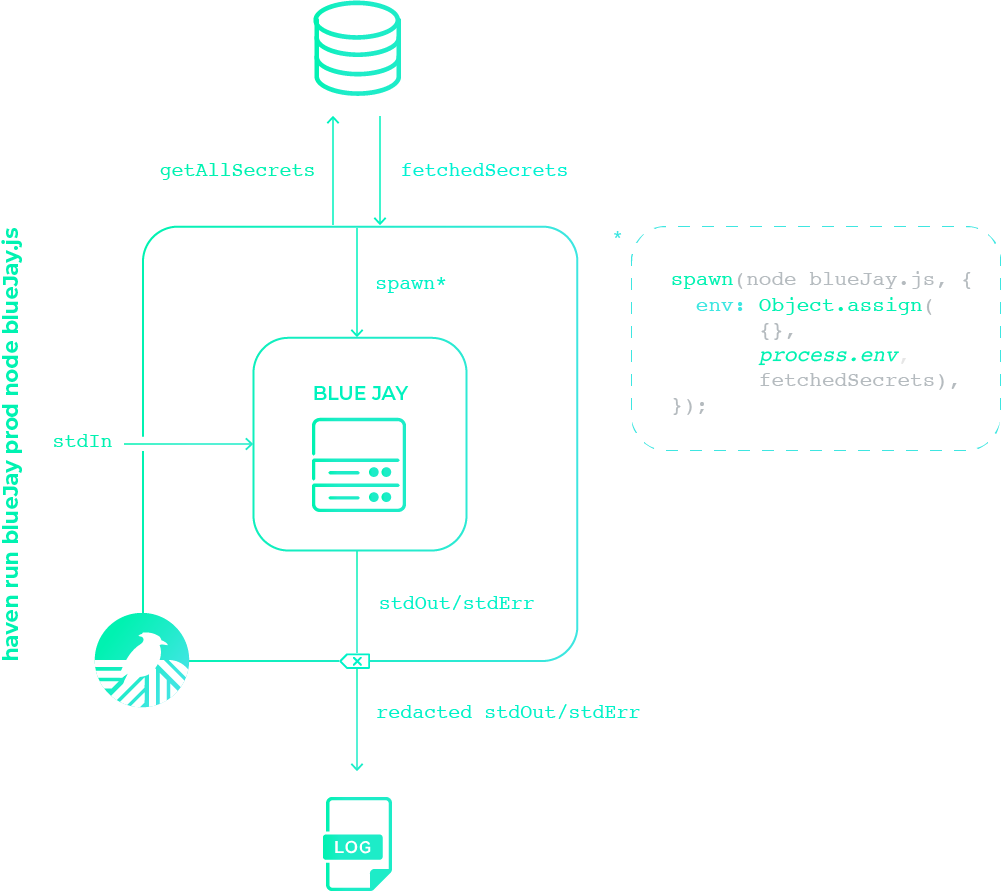
So how does this child process technique fit into the bigger
picture? In the example shown below, note that todos is the
Haven project, prod is the environment and nodemon todos.js is
the command that is run by Haven.
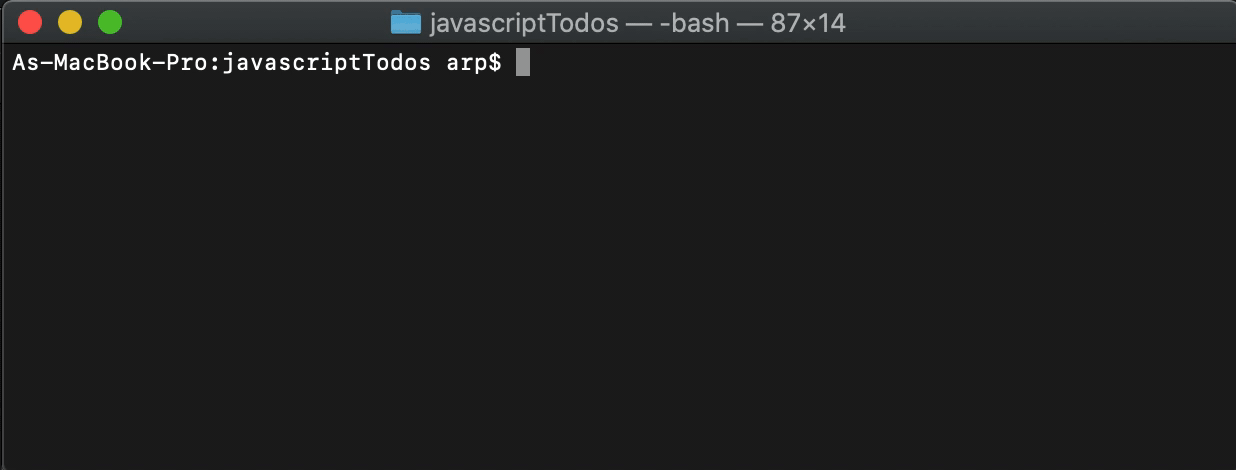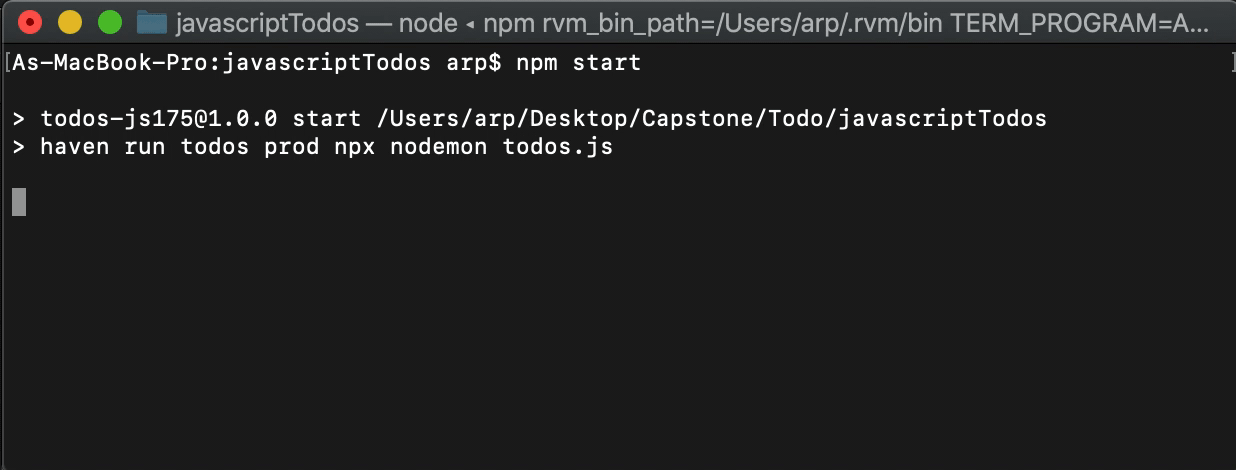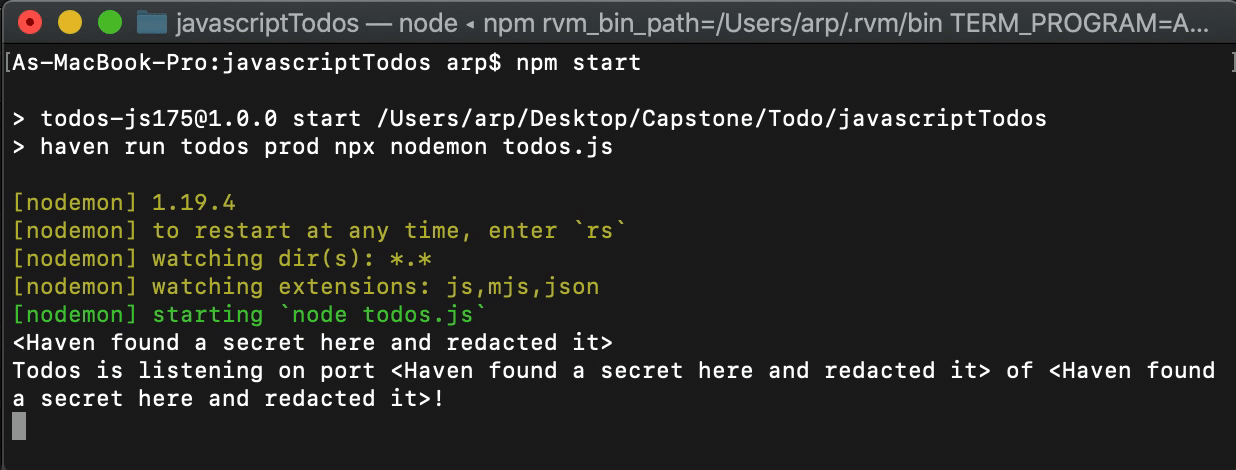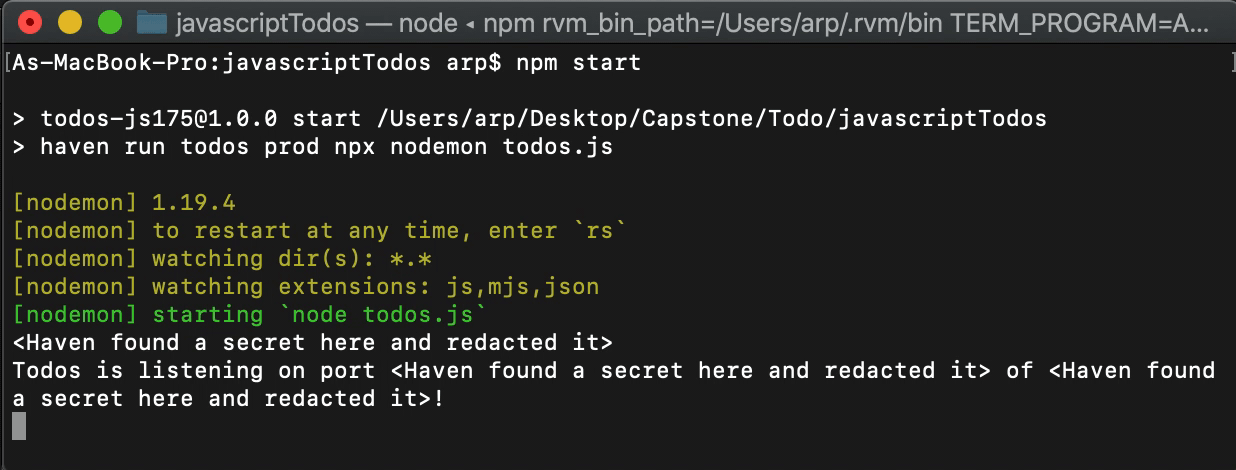
Haven fetches the secrets for the project/environment combination, then spawns a child process via the command you passed to Haven using the spawn method from the Node child process library. The secrets are injected into this child process as environment variables, making them available for the application. Then, as the application runs, Haven intercepts both standard output and standard error, redacts logged secrets, and logs the redacted result.
6 Future Work
And that's Haven! We're an open-source secrets manager for small teams, with a UI and CLI for easy team management. For our next steps, we plan to add the ability for users to add secrets in bulk from JSON and YAML files. We also plan to add an email integration to make new user creation even smoother.
In addition, we plan to support the option for per-secret access controls (rather than per-project access controls), as well as provide direct plug-ins and integrations with select credential providers to support dynamic secrets (i.e., one-time use credentials).
7 References
[1] https://www.hashicorp.com/resources/introduction-vault-whiteboard-armon-dadgar
[2] https://www.ndss-symposium.org/wp-content/uploads/2019/02/ndss2019_04B-3_Meli_paper.pdf
[3] https://www.digitalocean.com/blog/update-on-the-april-5th-2017-outage/
[4] https://www.capitalone.com/facts2019/
[5] https://12factor.net/config
[6] https://www.vaultproject.io/docs/internals/architecture
[6] https://en.wikipedia.org/wiki/Web_application_security#Security_threats
[8] https://www.envkey.com/faq/
[9] https://secrethub.io/docs/guides/environment-variables/
[10] https://www.honeybadger.io/blog/securing-environment-variables/
The Team



